2019年5月25日 下午10:17
1 | 6.PyTorch.pdf |
- Static_Dynamic_Graph
- 我终于理解图这个概念从哪来的的:【图】来源于求解梯度的反向传播算法,而PyTorch和Tensorflow只是实现了这种概念而已。
- Weight_Initialization
- 权重的初始化,我一直理解不深,觉得随便初始化效果都一样
- 这里的关键是他们是用什么衡量初始化的好坏?
- 他们将每层的输出(通过激活函数之后)的结果直方图画出来。
- 这个直方图不能全部集中在0、1、-1这些地方,而是应该有分布的分布在-1~1之间
- 如何找到好的初始化权重?
- 我认为他们就是试出来的
- Batch_Normalization
- 主要思想:
- 目的:和Weight_Initialization的目的相同,都是要让每层的输出满足合理的分布
- 方法:既然找到一个好的初始化权重很难,那么,我们就让每层不太好的输出,强行的转化为较好的分布
- 主要思想:
- Optimization
- SGD:就是简单的
负梯度大小 * 步长(学习率) - SGD+momentum:
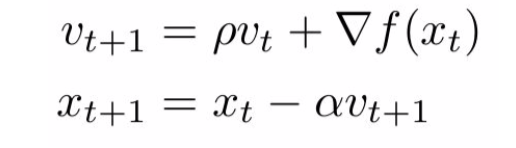
- 理解:要尽可能的维持上一步的速度,上下步之间有了关系
- Adam
- 理解:有一定的自适应性

- 猫咬自己的尾巴,有点类似于迭代运算
- 自己(x)影响下一轮的自己
- 理解:有一定的自适应性
- SGD:就是简单的