2020年4月5日 上午10:56
作为软件工程出身的人,我从子系统分解的角度,将操作系统分解,看看这个庞大的系统中包含哪些子系统
- 项目管理子系统(泛指)

- 项目应该有运行中的状态
- TASK_RUNNING 并不是说进程正在运行,而是表示进程在时刻准备运行的状态。这个时候,要看 CPU 小伙伴有没有空,有空就运行他,没空就得等着。
- 有时候,进程运行到一半,需要等待某个条件才能运行下去,这个时候只能睡眠。睡眠状态有两种。一种是 TASK_INTERRUPTIBLE,可中断的睡眠状态。这是一种浅睡眠的状态,也就是说,虽然在睡眠,等条件成熟,进程可以被唤醒。
- 另一种睡眠是 TASK_UNINTERRUPTIBLE,不可中断的睡眠状态。这是一种深度睡眠状态,不可被唤醒,只能死等条件满足。有了一种新的进程睡眠状态,TASK_KILLABLE,可以终止的新睡眠状态。进程处于这种状态中,他的运行原理类似 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号,也即虽然在深度睡眠,但是可以被干掉。
- 一旦一个进程要结束,先进入的是 EXIT_ZOMBIE 状态,但是这个时候他的父进程还没有使用 wait() 等系统调用来获知他的终止信息,此时进程就成了僵尸进程。

- 项目应该有运行中的状态
- 权限管理子系统
- (编译子系统)
- 不属于操作系统的一部分
- 编译其实是一个需求分析和需求转换的过程
- 最后生成ELF 格式的项目执行计划书,这个项目执行计划书有总论 ELF Header 的部分,有包含指令的代码段的部分,有包含全局变量的数据段的部分
- “你看,每次你接一个项目,总要写成项目执行计划书,CPU 小伙伴们才能执行吧,项目计划书中的一行一行指令运行过程中,免不了要产生一些数据。这些数据要保存在一个地方,这个地方就是会议室(内存)。会议室(内存)被分成一块一块儿的,都编好了号。例如 3F-10,就是三楼十号会议室。这个地址是实实在在的地址,通过这个地址我们就能够定位到物理内存的位置。”
- 任务管理子系统(专指内核态)
- 在 Linux 里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务,由一个统一的结构 task_struct 进行管理。

- 在 Linux 里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务,由一个统一的结构 task_struct 进行管理。
- 任务调度子系统
- 调度要解决的第一个问题是,每一个 CPU 小伙伴每过一段时间,都要想一下,白板上这么多项目,我应该干哪一个?CPU 的队列里面有这么多的进程或者线程,应该取出哪一个来执行?

- 调度要解决的第二个问题是,什么时候切换任务?也即,什么时候,CPU 小伙伴应该停下一个进程,换另一个进程运行?
- 调度要解决的第一个问题是,每一个 CPU 小伙伴每过一段时间,都要想一下,白板上这么多项目,我应该干哪一个?CPU 的队列里面有这么多的进程或者线程,应该取出哪一个来执行?
- 内存管理子系统
- 第一,物理内存的管理,相当于会议室管理员管理会议室;
- 对物理内存的管理系统,我们称为伙伴系统

- 对物理内存的管理系统,我们称为伙伴系统
- 第二,虚拟地址的管理,也即在项目组的视角,会议室的虚拟地址应该如何组织;
- 有了虚拟地址的管理这个规定以后,项目执行计划书ELF要写入数据的时候,就需要符合里面的规定了,数据不能随便乱放了。规定具体如下:
- 首先,这么大的虚拟空间一切二,一部分用来放内核的东西,称为内核空间;一部分用来放进程的东西,称为用户空间。
- 用户空间:
- 我们从最低位开始排起,先是 Text Segment、Data Segment 和 BSS Segment。Text Segment 是存放二进制可执行代码的位置,Data Segment 存放静态常量,BSS Segment 存放未初始化的静态变量。这些都是在项目执行计划书里面有的。
- 接下来是堆段。堆是往高地址增长的,是用来动态分配内存的区域,malloc 就是在这里面分配的。
- 接下来的区域是 Memory Mapping Segment。这块地址可以用来把文件映射进内存用的,如果二进制的执行文件依赖于某个动态链接库,就是在这个区域里面将 so 文件映射到了内存中。
- 再下面就是栈地址段了,主线程的函数调用的函数栈就是用这里的。
- 如果需要进行更高权限的工作,就需要调用系统调用,进入内核。
- 到了内核里面,无论是从哪个进程进来的,看到的是同一个内核空间,看到的是同一个进程列表。
- 虽然内核栈是各用各的,但是如果想知道的话,还是能够知道每个进程的内核栈在哪里的。所以,如果要访问一些公共的数据结构,需要进行锁保护。
- 内核的代码访问内核的数据结构,大部分的情况下都是使用虚拟地址的。
- 虽然内核代码权限很大,但是能够使用的虚拟地址范围也只能在内核空间,也即内核代码访问内核数据结构
- 在内核里面也会有内核的代码,同样有 Text Segment、Data Segment 和 BSS Segment,内核代码也是 ELF 格式的。
- 第三,虚拟地址和物理地址如何映射的问题,也即会议室管理员如果管理映射表。
- 两级:
- 虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址。这个基地址与页内偏移的组合就形成了物理内存地址。
- 32 位环境下,虚拟地址空间共 4GB。如果分成 4KB 一个页,那就是 1M 个页。每个页表项需要 4 个字节来存储,那么整个 4GB 空间的映射就需要 4MB 的内存来存储映射表。如果每个进程都有自己的映射表,100 个进程就需要 400MB 的内存。对于内核来讲,有点大了 。
- 三级:32位
- 页目录有 1K 项,用 10 位就可以表示访问页目录的哪一项。这一项其实对应的是一整页的页表项,也即 4K 的页表项。每个页表项也是 4 个字节,因而一整页的页表项是 1k 个。再用 10 位就可以表示访问页表项的哪一项,页表项中的一项对应的就是一个页,是存放数据的页,这个页的大小是 4K,用 12 位可以定位这个页内的任何一个位置。
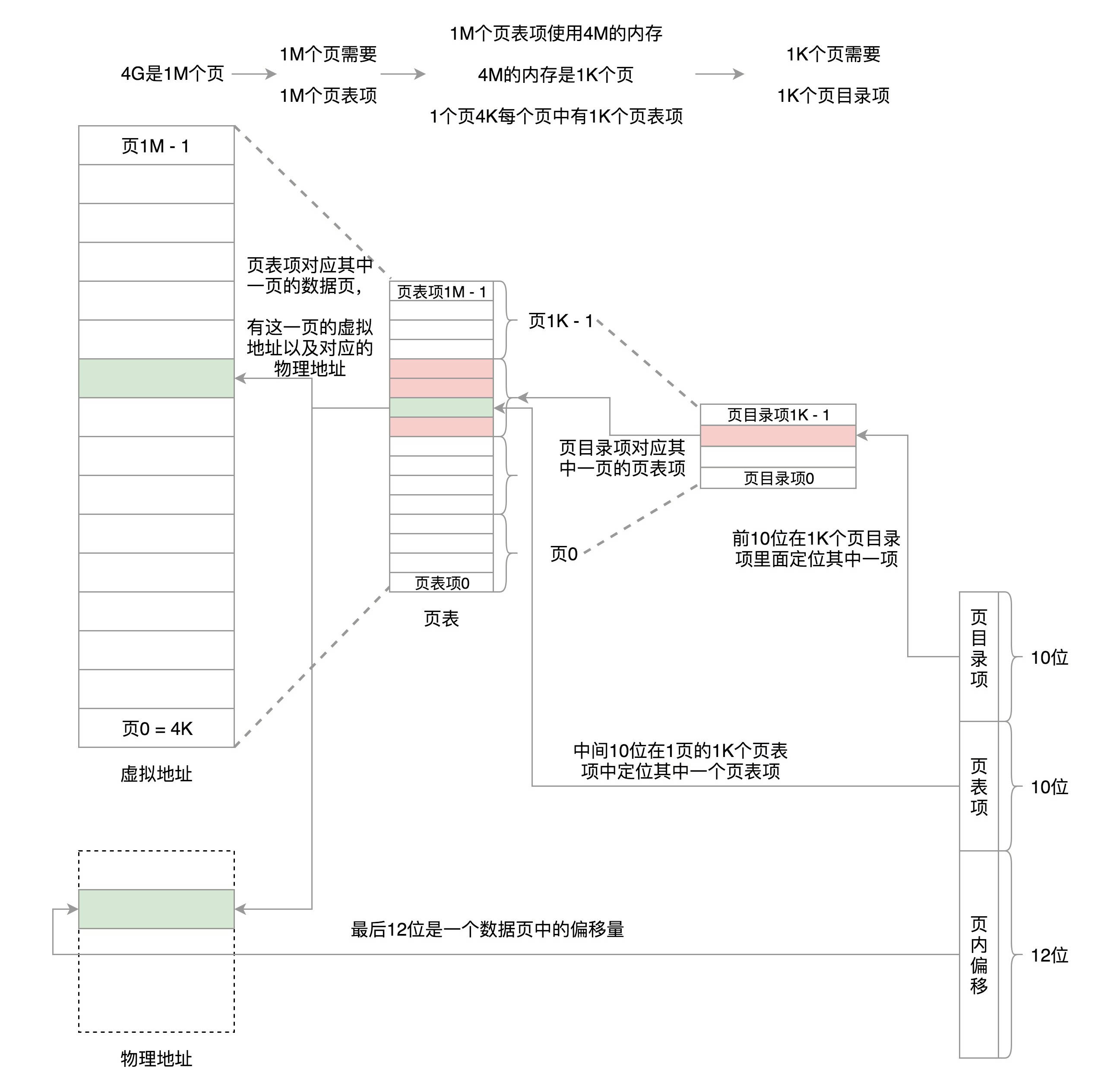
- 页目录有 1K 项,用 10 位就可以表示访问页目录的哪一项。这一项其实对应的是一整页的页表项,也即 4K 的页表项。每个页表项也是 4 个字节,因而一整页的页表项是 1k 个。再用 10 位就可以表示访问页表项的哪一项,页表项中的一项对应的就是一个页,是存放数据的页,这个页的大小是 4K,用 12 位可以定位这个页内的任何一个位置。
- 四级:64位
- 两级:
- 第一,物理内存的管理,相当于会议室管理员管理会议室;
- 文件管理系统
- 第一点,文件系统要有严格的组织形式,使得文件能够以块为单位进行存储。
- 第二点,文件系统中也要有索引区,用来方便查找一个文件分成的多个块都存放在了什么位置。
- 第三点,如果文件系统中有的文件是热点文件,近期经常被读取和写入,文件系统应该有缓存层。
- 第四点,文件应该用文件夹的形式组织起来,方便管理和查询。
- 第五点,Linux 内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用。
- 对于每一个进程,打开的文件都有一个文件描述符。files_struct 里面会有文件描述符数组。每个一个文件描述符是这个数组的下标,里面的内容指向一个 struct file 结构,表示打开的文件。这个结构里面有这个文件对应的 inode,最重要的是这个文件对应的操作 file_operation。如果操作这个文件,就看这个 file_operation 里面的定义了。
- 输入和输出系统子系统
- (设备控制管理子系统)
- 第一层,用设备控制器屏蔽设备差异。
- 这里需要注意的是,设备控制器不属于操作系统的一部分,但是设备驱动程序属于操作系统的一部分。
- 操作系统的内核代码可以像调用本地代码一样调用驱动程序的代码,而驱动程序的代码需要发出特殊的面向设备控制器的指令,才能操作设备控制器。
- 设备驱动管理子系统
- 第二层,用驱动程序屏蔽设备控制器差异。
- 接受外部信息(中断)管理子系统
- 第三,用中断控制器统一外部事件处理。
- 对外输出信息管理子系统(在文件子系统中集成)
- 第四,用文件系统接口屏蔽驱动程序的差异。
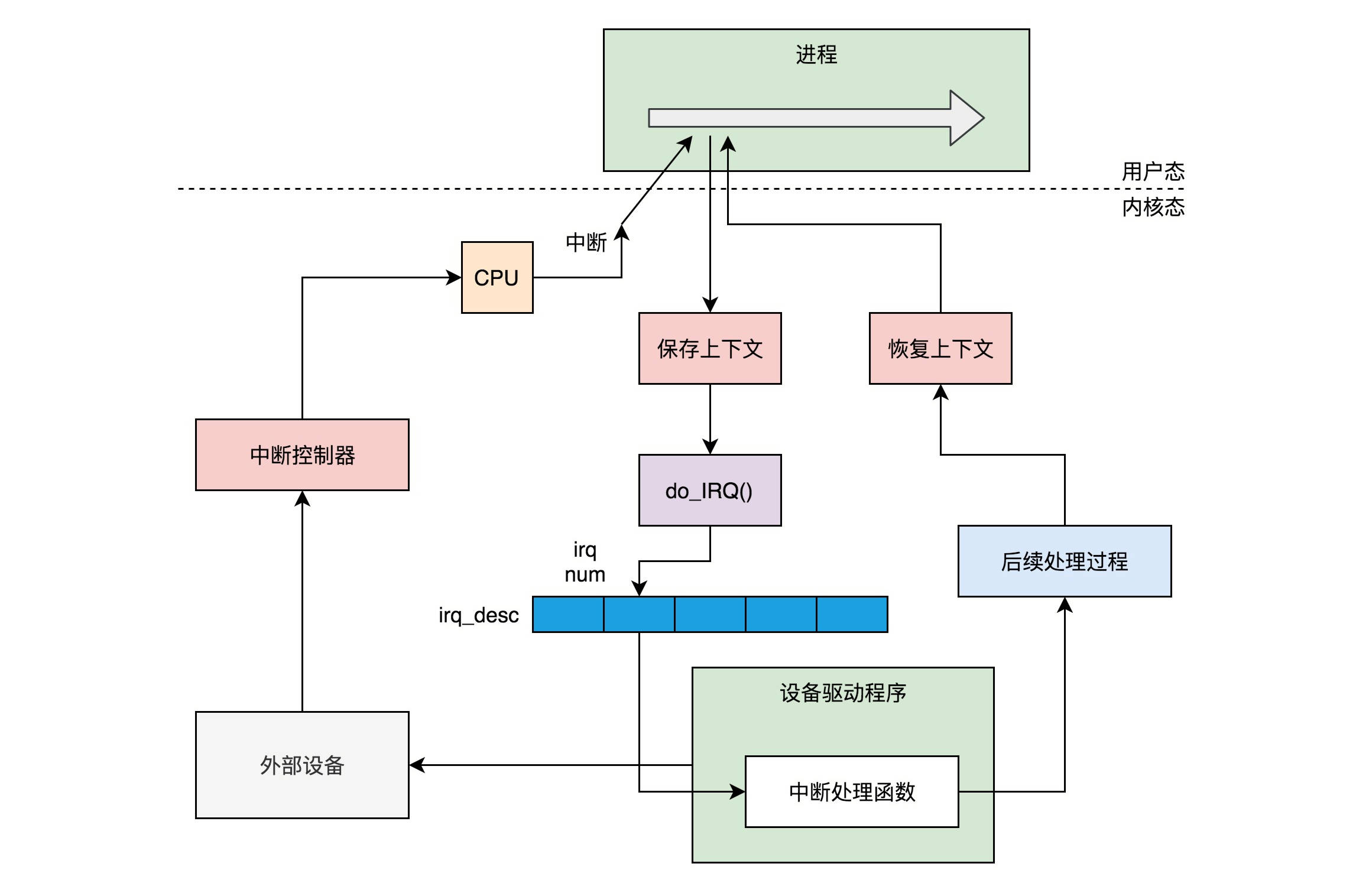
- 一般的流程是,一个设备驱动程序初始化的时候,要先注册一个该设备的中断处理函数。咱们讲进程切换的时候说过,中断返回的那一刻是进程切换的时机。中断的时候,触发的函数是 do_IRQ。这个函数是中断处理的统一入口。在这个函数里面,我们可以找到设备驱动程序注册的中断处理函数 Handler,然后执行他进行中断处理。
- (设备控制管理子系统)
- 异常处理子系统
- 信号可以在任何时候发送给某一进程,进程需要为这个信号配置信号处理函数。当某个信号发生的时候,就默认执行这个函数就可以了。
- 网络子系统:
- 操作系统对于网络协议的实现模式是这样的:
- 二到四层的处理代码在内核里面,七层的处理代码让应用自己去做。两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是 Socket。应用层和内核互通的机制,就是通过 Socket 系统调用
- 整个网络过程:
- 如果公司想要和其他公司沟通,我们将请求封装为 HTTP 协议,通过 Socket 发送到内核。内核的网络协议栈里面,在 TCP 层创建用于维护连接、序列号、重传、拥塞控制的数据结构,将 HTTP 包加上 TCP 头,发送给 IP 层,IP 层加上 IP 头,发送给 MAC 层,MAC 层加上 MAC 头,从硬件网卡发出去。
- 最终网络包会被转发到目标服务器,它发现 MAC 地址匹配,就将 MAC 头取下来,交给上一层。IP 层发现 IP 地址匹配,将 IP 头取下来,交给上一层。TCP 层会根据 TCP 头中的序列号等信息,发现它是一个正确的网络包,就会将网络包缓存起来,等待应用层的读取。
- 应用层通过 Socket 监听某个端口,因而读取的时候,内核会根据 TCP 头中的端口号,将网络包发给相应的应用。
- 操作系统对于网络协议的实现模式是这样的:
- 虚拟化子系统:
- 第一种方式,完全虚拟化。
- 其实说白了,这是一种“骗人”的方式。虚拟化软件会模拟假的 CPU、内存、网络、硬盘给到虚拟机,让虚拟机里面的内核自我感觉良好,感觉他终于又像个内核了。在 Linux 上,一个叫作 qemu 的工具可以做到这一点。
- qemu 向虚拟机里面的客户机操作系统模拟 CPU 和其他的硬件,骗客户机,GuestOS 认为自己和硬件直接打交道,其实是同 qemu 模拟出来的硬件打交道,qemu 会将这些指令转译给真正的硬件。由于所有的指令都要从 qemu 里面过一手,因而性能就会比较差。
- 第二种方式,硬件辅助虚拟化
- 可以使用硬件 CPU 的 Intel-VT 和 AMD-V 技术,需要 CPU 硬件开启这个标志位(一般在 BIOS 里面设置)。当确认开始了标志位之后,通过内核模块 KVM,GuestOS 的 CPU 指令将不用经过 Qemu 转译,直接运行,大大提高了速度。qemu 和 KVM 融合以后,就是 qemu-kvm。
- 第三种方式称为半虚拟化
- 对于网络或者硬盘的访问,我们让虚拟机内核加载特殊的驱动,重新定位自己的身份。虚拟机操作系统的内核知道自己不是物理机内核,没那么高的权限。他很可能要和很多虚拟机共享物理资源,所以学会了排队。虚拟机写硬盘其实写的是一个物理机上的文件,那我的写文件的缓存方式是不是可以变一下。我发送网络包,根本就不是发给真正的网络设备,而是给虚拟的设备,我可不可以直接在内存里面拷贝给它,等等等等。
- 网络半虚拟化方式是 virtio_net,存储是 virtio_blk。客户机需要安装这些半虚拟化驱动。客户机内核知道自己是虚拟机,所以会直接把数据发送给半虚拟化设备,然后经过特殊处理(例如排队、缓存、批量处理等性能优化方式),最终发送给真正的硬件。这在一定程度上提高了性能。
- 第一种方式,完全虚拟化。
一个子系统:系统都是服务行业,被别人调用的
- 系统结构:有哪些组成部分,各个部分之间的关系
- 系统运转流程图:这个过程中可能会涉及到不同的数据结构算法