2017年9月13日 下午4:15
先确定存储结构然后搭配相应的算法
前面的第一章就是我们要考虑的知识点,这个是死的
基础知识点是重点,掌握之后算法其实是很好写的,正如我以前所说的
2017年9月13日 下午4:15
先确定存储结构然后搭配相应的算法
前面的第一章就是我们要考虑的知识点,这个是死的
基础知识点是重点,掌握之后算法其实是很好写的,正如我以前所说的
2017年9月13日 下午4:15
通过这次实验,我实现了快排和二分归并排序。在快排中,主要是先part函数,进行分解,并且在分解的同时排好序,从分治的角度去开,快排其实是侧重于分治中的第一步分解,然后,省略了合并。在分解的过程中关键的两点就是边界和过程的模拟,同样也是大量例子的分析和尝试才是完全弄清楚。接下来是第二个实验二分归并排序,二分归并排序,同样,一开始有很多的细节不清楚,比如说当是奇数时如何处理,这个解决办法就是通过举一个三个数的例子来尝试,发现第一个和第二数为一组,而第三个数为第二组。然后就按分治规定的方法写,但是写到最后的时候发现一个问题,排出来的顺序,即使是错了,错的也一定规律没有,然后我用断点,不断的输出断点信息,终于发现二分归并需要大量的空间,这是我在一开始没有想到的。改正后我又发现一个问题,就是他在合并的时候,总有一部分树的分支没有合并,导致了结果出错,最后我同样通过断点方法解决了,发现其实是边界处理的问题,这就体现除了在写递归的时候,边界处理是一个特别关键的问题。
这个背包问题最难的地方是去理解他的递推方程,它使用(k-1,y)和(k,y-m[k-1][0])+ m[k-1][1]分别求没放入第k个在y限制下的最大值,以及放入第k个在y-m[k-1][0]限制下的最大值。这两个进行比较求最大值。但是有这个是仅仅不够的,当测试值为(1 1,1 2)时,就会发现求出来的值比实际的值多一,根据追踪现象来看,其实是当y-m[k-1][0]<0 时会出现这样的问题,说明这里是少一个约束。从这道题中可以看出,在写程序中,思路是一部分,其实还有一部分重要的内容都包含了约束,约束有很多不是自己能够直接想出来的,需要我们在写程序的时候不断的进行数据测试,和自己笔算的结果进行对比来进行发下。
mergetSort
1 | // |
quickSort
1 | // |
背包
1 | // |
2017年9月12日 下午6:13
TP从执行的步骤上来开,真正项目的启动放在最后一步
前面90%的步骤都是在读取配置文件
这说明给了一个道理:
1. 读取配置文件,并进行设置就是框架的主要工作,这些都在项目启动前完成。
2. 与之对应的是,我们在使用框架的时候回会写大量的的配置文件,这下就知道原因了
2017年9月12日 下午5:26
JSP页面实现批量删除数据 - 饮冰室人的博客 - CSDN博客
(我这里没有听,我觉得自己看看也就会了,需要使用这个功能的时候去对应的项目去找源代码就行了)
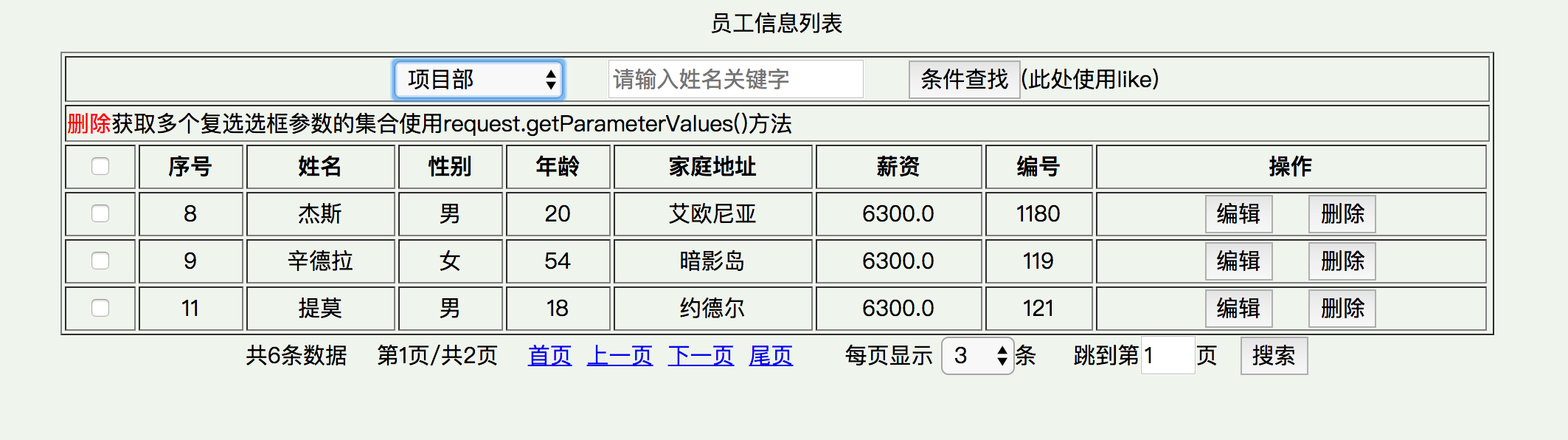
效果图1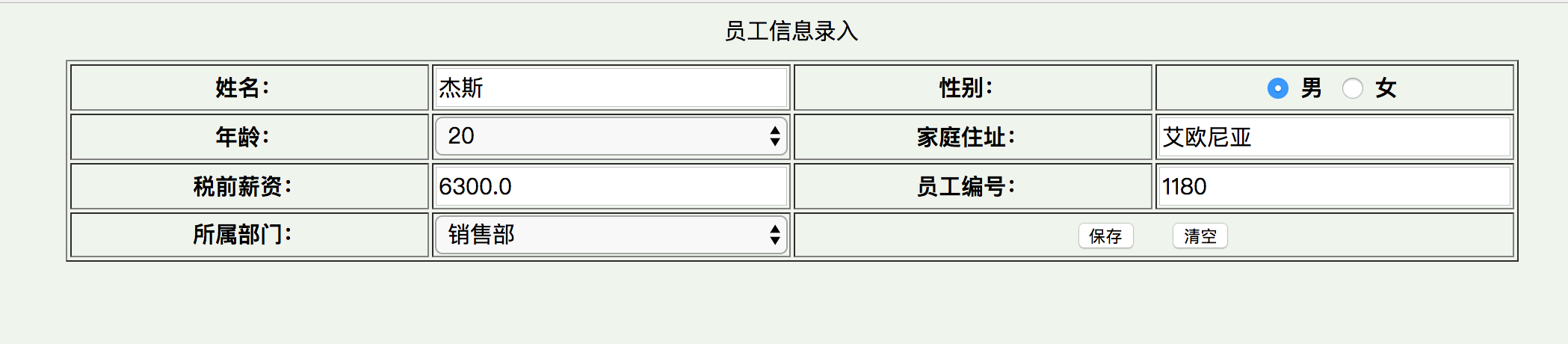
效果图2
我先说说我在拼凑整个基础项目过程中遇到的问题,这里有已经解决的,还有没有解决的问题。其次,我在把各个功能简单的介绍一下,方便以后回忆。
/* str+=“<div align=‘center’><jsp:include page=‘/page.jsp’></jsp:include></div>" */2017年9月12日 下午4:15
附录:一些资料
这是一篇以前对我启发比较大的一篇文章:
五大常用算法:分治、动态规划、贪心、回溯和分支界定 - yapian8的专栏 - CSDN博客
2017年9月12日 下午2:54
2017年9月11日 上午11:55
2017年9月11日 上午9:23
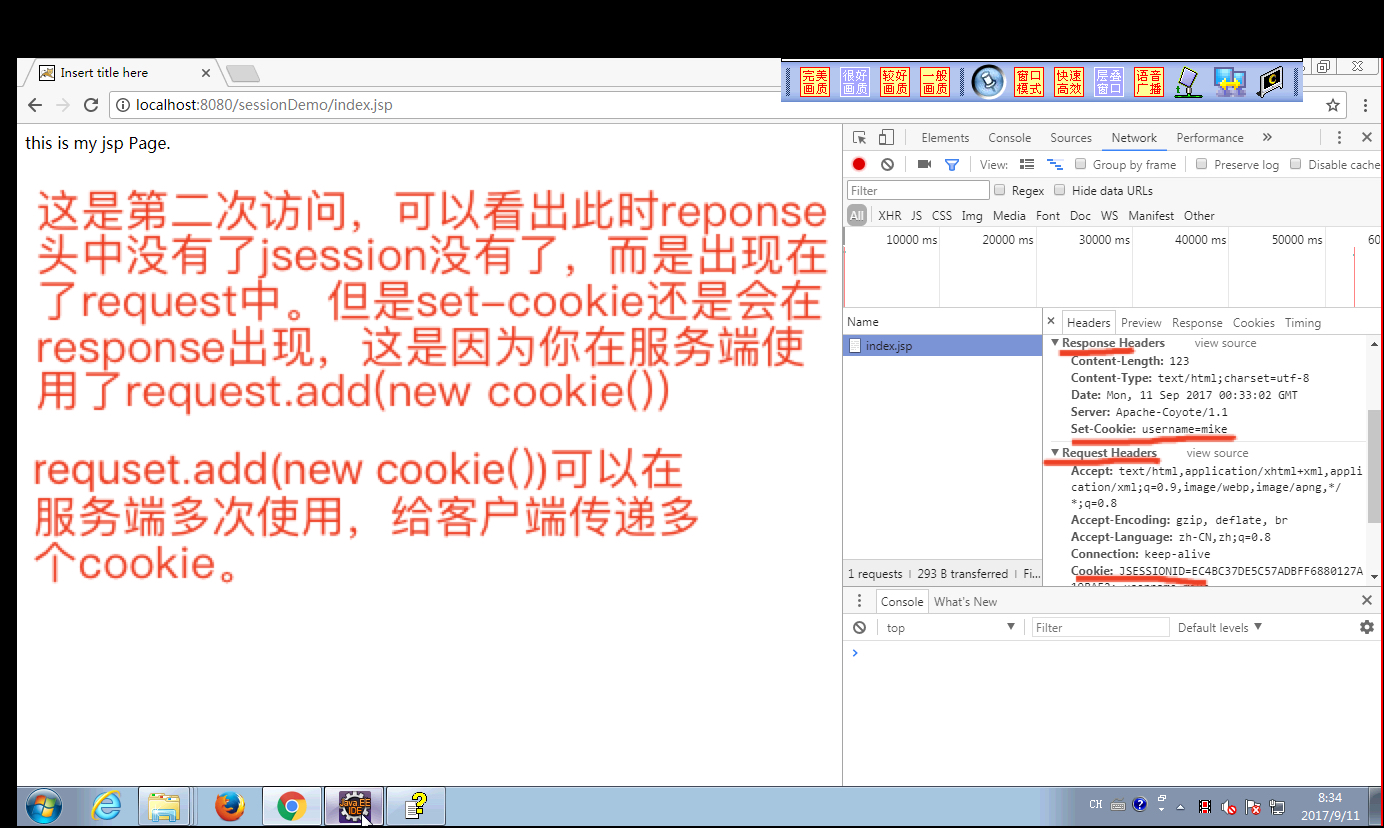
可以从http报文头中去观察cookie的过程
直接看这个txt文档排版比较整齐,下面那个是为了方便粘贴复制
cookie和session.txt
1 | ================================ |
2017年9月11日 上午8:23
1 | 请求响应对象 |
1 | response对象 |
1 | request |
1 |
|
1 | 乱码 |