2020年3月16日 下午5:11
补充:2020年5月20日 下午7:26
- 所谓的异常catch其实就是一个函数调用
定义:
编译器会自动调用析构函数,包括在函数执行发生异常的情况。在发生异常时对析构函数的调用,还有一个专门的术语,叫栈展开(stack unwinding)
实例代码:
1 |
|
执行代码的结果是:
1 | Obj() |
也就是说,不管是否发生了异常,obj 的析构函数都会得到执行。
2020年3月16日 下午5:11
补充:2020年5月20日 下午7:26
编译器会自动调用析构函数,包括在函数执行发生异常的情况。在发生异常时对析构函数的调用,还有一个专门的术语,叫栈展开(stack unwinding)
1 |
|
1 | Obj() |
也就是说,不管是否发生了异常,obj 的析构函数都会得到执行。
2020年3月16日 下午5:08
1 | void foo(int n) |
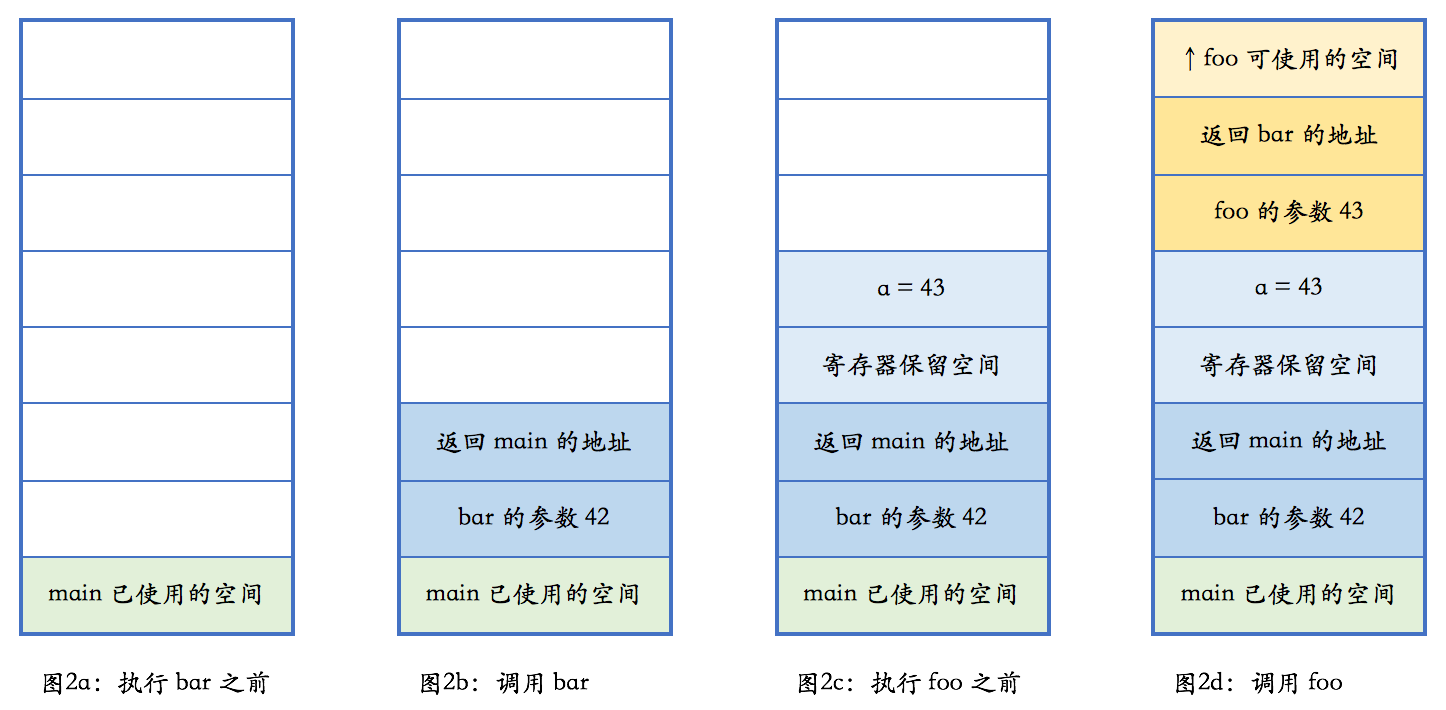
2020年3月16日 下午4:58
2020年3月16日 下午4:55
test01_unique_ptr.cpp
1 |
|
2020年3月16日 下午4:41
smart_ptr<circle> ptr1(new circle());这里面new circle()产生的对象是分配在堆上的,不受main()函数作用域限制,需要我们手动进行释放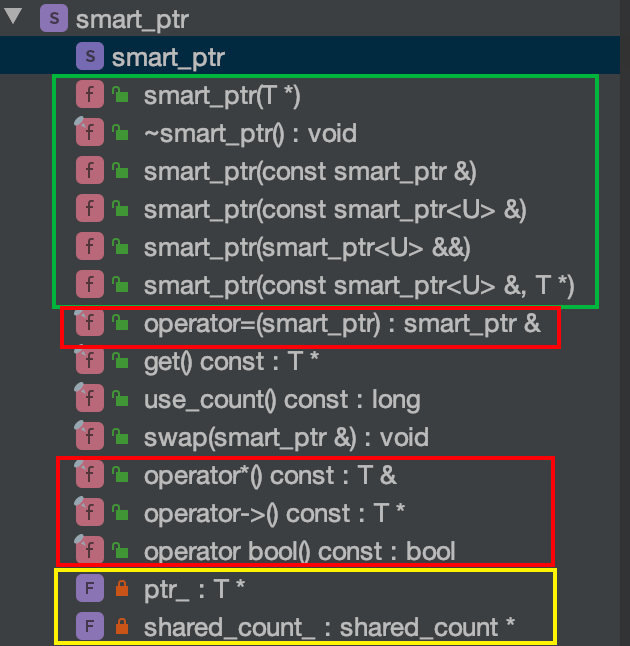
1 |
|
shape.h
1 |
|
smart_ptr.h
1 |
|
2020年3月16日 下午2:56
/IMG_0292.JPG)
[摘抄]C++异常处理的编程方法系列
不能在析构函数里面抛出异常:涉及到C++异常处理的理解
类型转换的三个层次
串讲:基本关键字、类型转换、运行时类型识别、重载运算、OOP、模板泛型
什么是锁、互斥量、原子操作解决不了的并发问题实例
从C++和Java对比的角度理解并发编程的本质
C++并发编程-锁、互斥量、原子操作的区别与联系锁、互斥量、原子操作
并发编程实例-反例的改进实例
异常的概念+自带的语法功能异常
函数式编程的实现手段:函数对象类函数对象
模板:模板、泛型编程和静态多态模板
从【移动构造】的意义,来学习值类别、值类型、生命周期、表达式类型移动构造
C++栈调用过程:C++自带功能
栈展开:C++自带功能
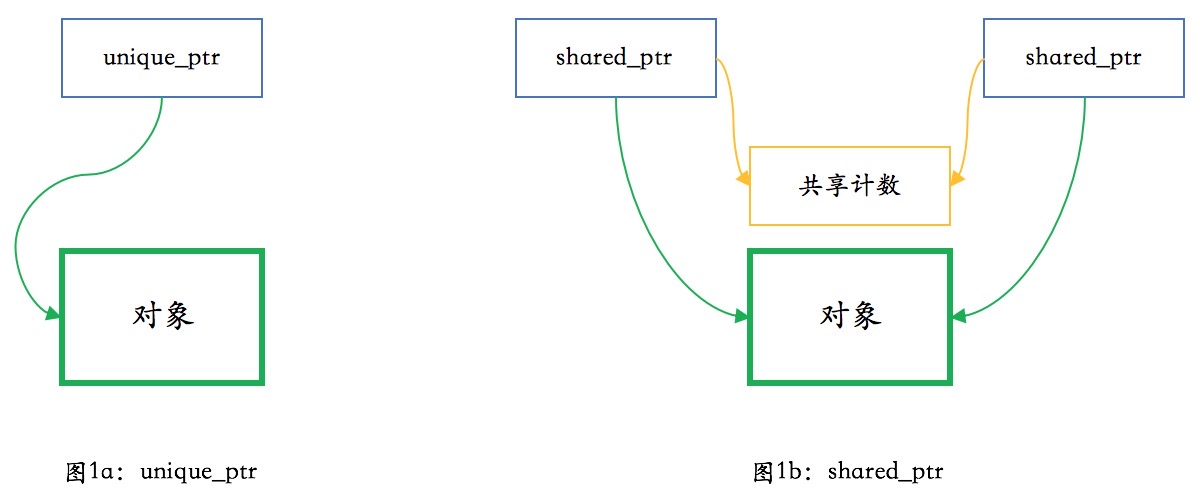
自己实现smart_ptr
自己实现unique_ptr
基础知识点1:堆、RALL、内存管理器
2020年3月15日 下午11:45
此项目是机器学习(Machine Learning)、深度学习(Deep Learning)、NLP面试中常考到的知识点和代码实现,也是作为一个算法工程师必会的理论基础知识。
2020年3月15日 下午10:59
2020年3月15日 下午10:47