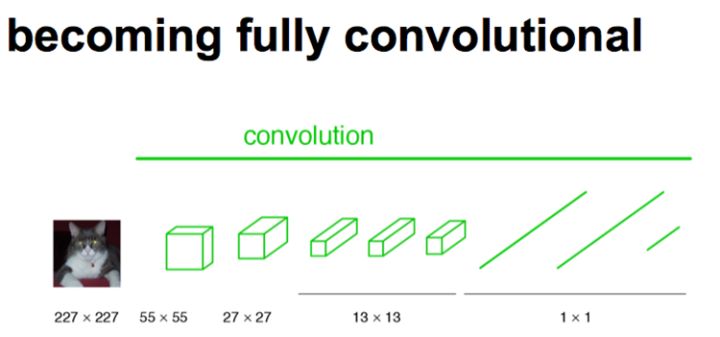
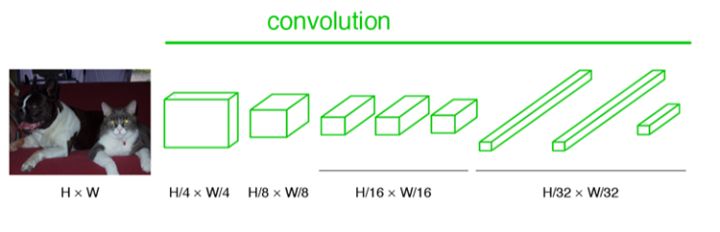
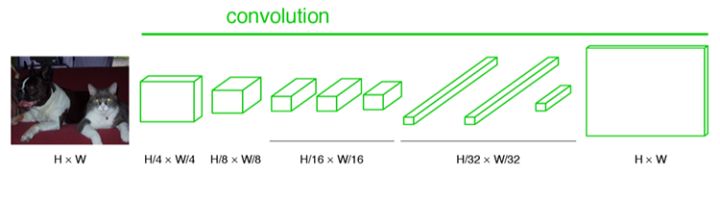
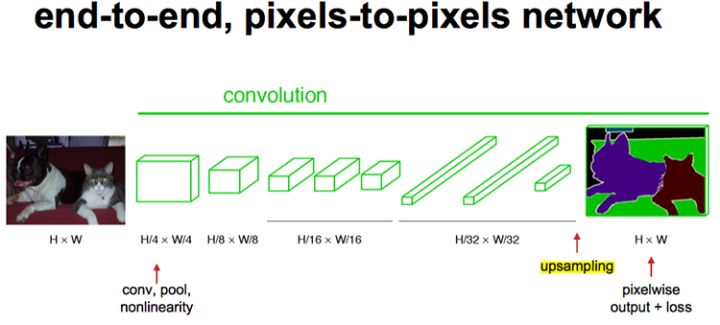
traceroute 124.16.78.118 traceroute to 124.16.78.118 (124.16.78.118), 64 hops max, 52 byte packets 1 10.8.0.1 (10.8.0.1) 16.493 ms 7.568 ms 7.478 ms 2 124.16.77.252 (124.16.77.252) 9.026 ms 9.670 ms 8.651 ms 3 * * * 4 * * * 5 * * * ^C
没有连接
1 2 3 4
~ traceroute 210.76.196.40 traceroute to 210.76.196.40 (210.76.196.40), 64 hops max, 52 byte packets 1 10.8.0.1 (10.8.0.1) 8.979 ms 16.738 ms 7.795 ms 2 10.8.0.1 (10.8.0.1) 7.886 ms !Z 7.787 ms !Z 7.757 ms !Z
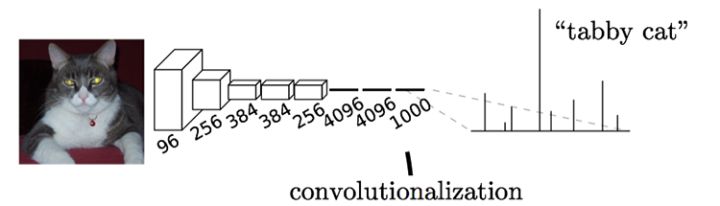
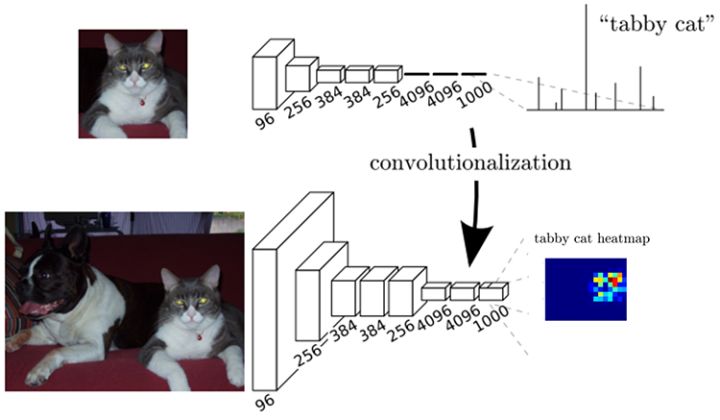
Evaluating the original ConvNet (with FC layers) independently across 224x224 crops of the 384x384 image in strides of 32 pixels gives an identical result to forwarding the converted ConvNet one time.