2019年6月15日 下午5:42
理解数学:
数学是一种思考方式:数学与编程
浅谈物理公式中的意义:=代表着物理量之间的依赖关系
正确理解物理公式:物理意义!=数学意义
数学是我们思维科学化的工具
如何培养数学兴趣
数学的本质作用
我提出的问题1:
2019年6月15日 下午5:32
2019年4月29日 下午7:41
理解矩阵:特征向量和特征值两种用途
PCA原理讲解
2019年3月31日 下午6:01
转:Viewing Matrices & Probability as Graphs
2019年3月30日 下午12:27
从历史发展的角度理解线性代数+微积分,及其关系
2019年3月16日 下午4:17
数学建模的方法和步骤
2019年3月12日 上午11:00
数学的本质作用
2019年3月11日 下午4:00
不同的数学模型
2019年3月11日 下午4:00
科研的小tip-部分内容是数学
数学上的推导类别
三维重建(点云)
特征向量:这部分已经是过时的了,可以看上面最新总结的
1. 图像处理之特征值和特征向量的意义
2. 如何理解矩阵特征值?
3. 矩阵特征值和椭圆长短轴的关系
旧:
数学是一种思考方式:数学与编程好文
浅谈物理公式中的意义:=代表着物理量之间的依赖关系
正确理解物理公式:物理意义!=数学意义
数学是我们思维科学化的工具
如何培养数学兴趣指出了数学中三个重要的能力
概率论:参数估计
机器学习的核心步骤
理解数学在ML中的使用
概率论:
复习18讲
概率(mindnote)
我提出的问题1:
前馈神经网络
微分学
2019年6月13日 下午6:39
一个餐馆,有各个包间
2019年6月13日 下午2:07

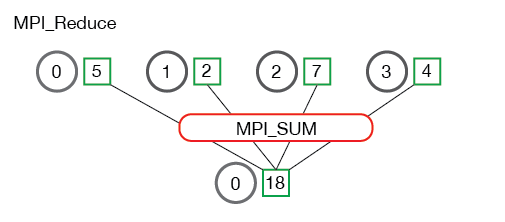
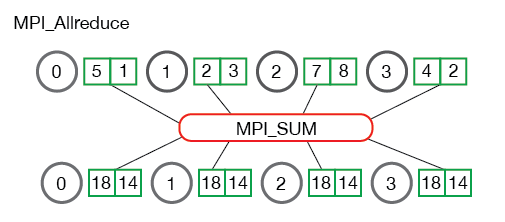
be "programmed" by the application developer.2019年6月13日 下午1:30
2019年6月13日 下午1:27
2019年7月15日 上午10:40
GPU并行
从数组的角度整理一个MP\MPI\GPU
2019年7月4日 下午7:45
GPU内存模型
2019年6月25日 下午2:42
MP_MPI_GPU对比
2019年6月15日 下午3:52
MPI自己的总结
2019年6月13日 下午1:42
推荐的一些资料
MP和MPI之间的对比
OpenMP总结
2019年5月29日 下午9:44
fail sharing (cache line)
2019年5月24日 下午9:14
OpenMP教程
2019年6月13日 下午1:26
2019年7月26日 下午6:21
GPU服务器使用
2019年7月4日 下午7:55
GPU执行
2019年6月13日 下午1:41
MPI安装执行
Mac中OpenMP环境安装
(openmp的编译运行)动态链接库与静态链接库
2019年6月6日 上午10:42
2019年6月6日 下午5:04
bounding box regression - CaffeCN深度学习社区
边框回归(Bounding Box Regression)详解 - 南有乔木NTU的博客 - CSDN博客
