2018年8月3日 下午3:54
这篇文章中有详细的分析步骤:
POJ2413 How many Fibs?【高精度】【二分】 - CSDN博客
1 |
|
2018年8月3日 下午3:54
这篇文章中有详细的分析步骤:
POJ2413 How many Fibs?【高精度】【二分】 - CSDN博客
1 |
|
2018年8月2日 下午3:54
199. Binary Tree Right Side View - CSDN博客
199. Binary Tree Right Side View这篇是老师的写法,但是我去理解的时候总觉得这种方法让我想的话十分的困难,难点在于:这种解法将问题巧妙的变换成了另一个遍历队列的问题,看似巧妙,但是给人的理解造成了比较大的困难。我觉得这样的并不能说是一个很好的算法,很好的算法应该让人一下就明白。
而,我在网上找到的这个两个解法,依靠的是树的BFS和DFS这两个基本的算法。我们要做的是根据题意,在原先的解法上面找出更改和创新的地方,弄清楚我们要在原先的基础上做什么。
BFS中,我们需要找到在保存的队列中,每层最右边的那个节点的位置。
DFS中,我们需要采用右序遍历,并找到判断 (每层最右边的那个节点的位置)的条件
2018年7月28日 下午4:01
『不羁阁』 | Walking Boy’s Blog - CSDN博客
现在我的思考方式:一定要联想到自己用过的方法和题(工具),这样思考问题才有下手点,不累。然后,要找到这道题中新的方法,总结下来,方便下次使用
pos = (strlen(s)-i-1)*N; //计算浮点数s^N小数点后的位sort(Num,Num+N);2018年7月24日 上午10:23
2018年12月7日 下午6:40
XML
数据库在整个知识体系中的位置
分布式的整体理解
2019年4月7日 下午6:40 旧
ORCALE SQL语法总结
2【SQL如何分析(SQL测试题)】
PLSQL(PLSQL语法+存储过程+触发器)
表复制(根据一个表创建另一个表)
数据库中索引+事务+sequence
SQL表连接
4【关于聚合函数注意事项】
3【SQL相关子查询的补充】
5【SQL的执行顺序】
1【SQL书本笔记摘抄】
数据库中定时处理数据+常用操作
2018年7月24日 下午8:22
这节使用的是keras框架,keras是对TensorFlow的进一步封装,写起来就和普通的程序一样了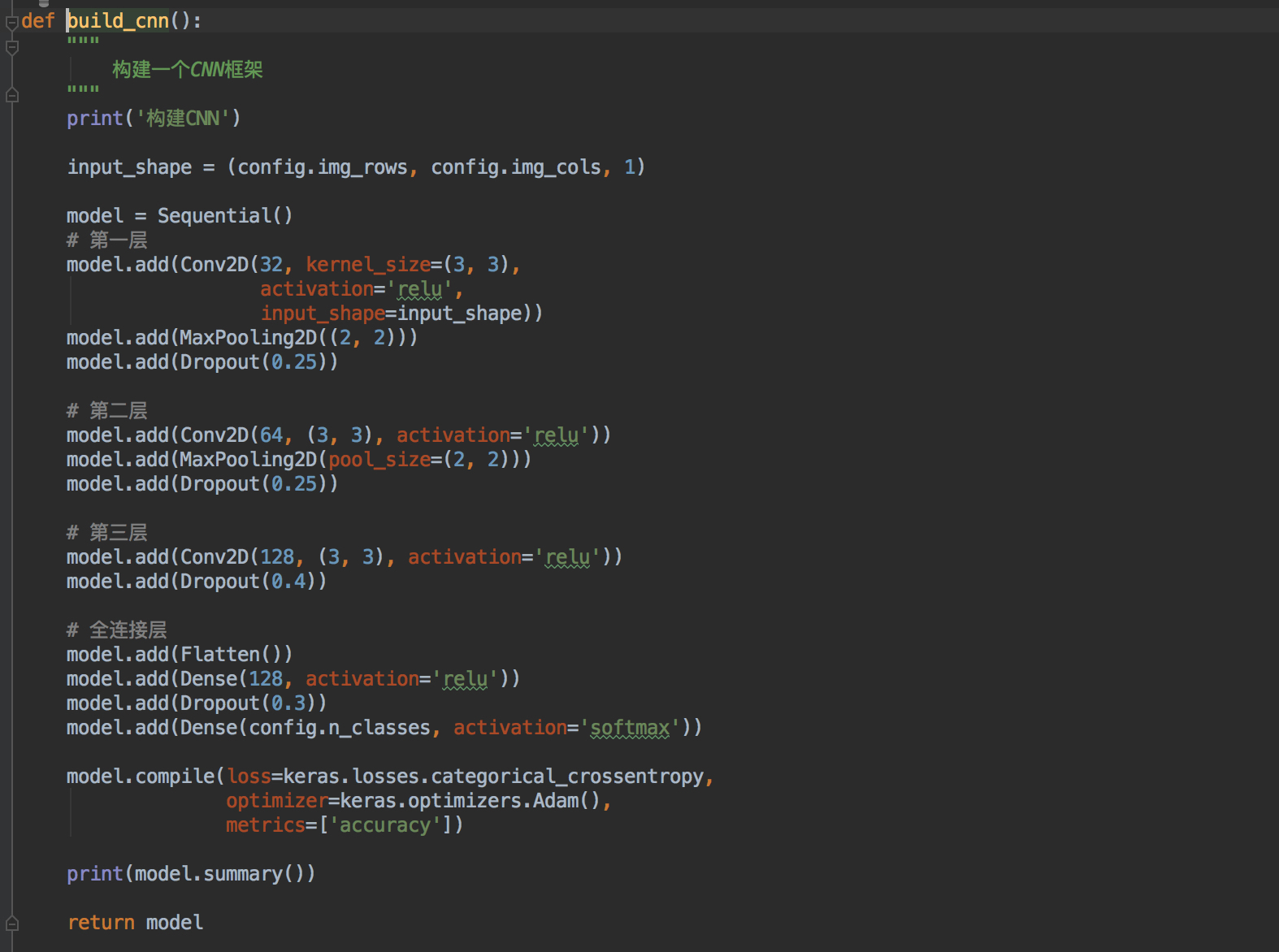
2018年7月24日 下午2:22
这个项目用到的方法,目的还是预测手机价格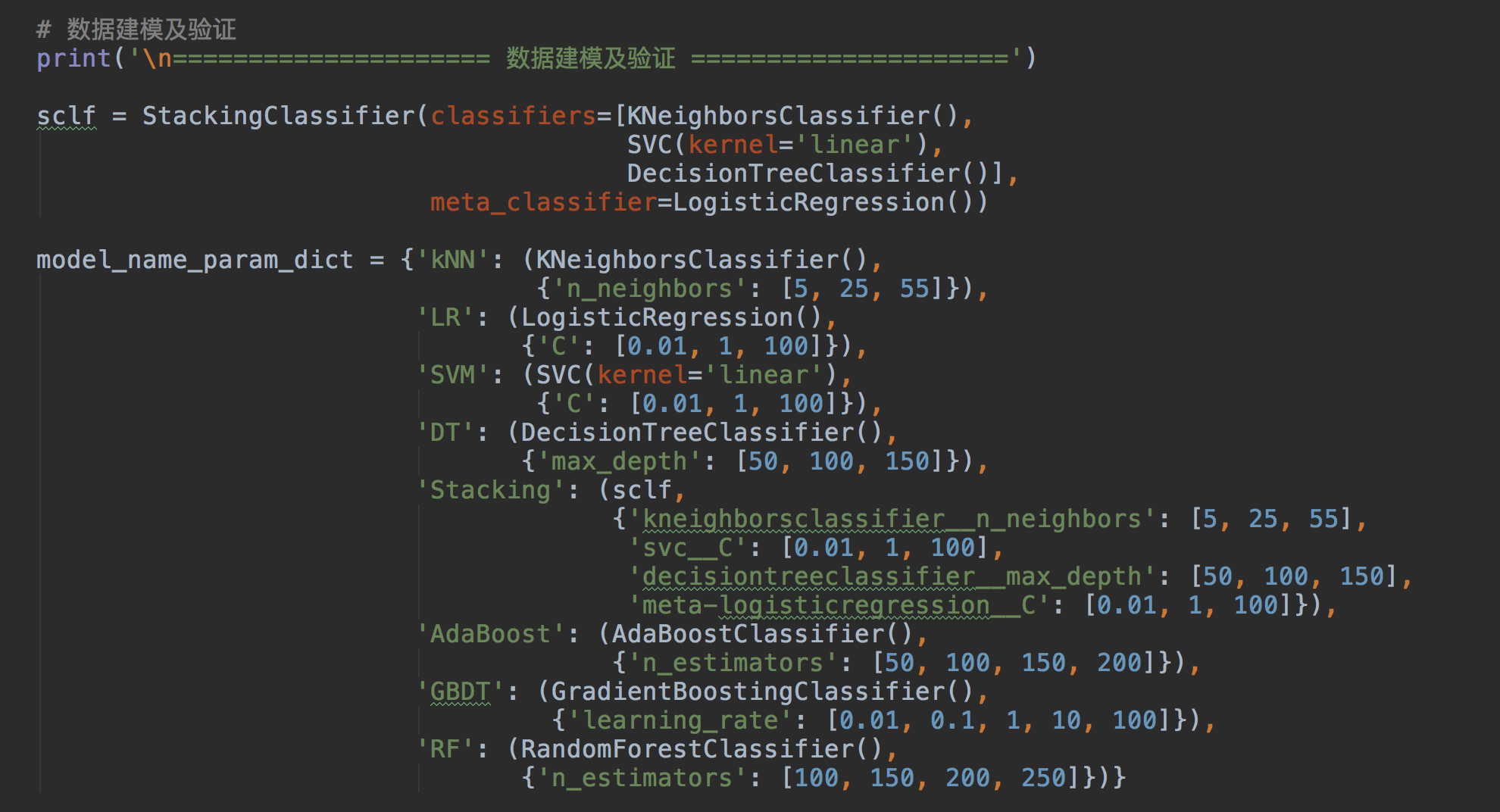
2018年7月24日 下午2:02
GBDT(MART) 迭代决策树入门教程 | 简介 - CSDN博客
本文对c4.5分类树,回归树,GBDT核心等概念做出来清晰的解释。

