2018年3月5日 下午2:55
前提:
- 我这篇文章的依据是第一课和第二课的中的关于PM2.5的两个项目,一个使用numpy一个使用pandas
理解pandas的过人之处:
- 核心理解方式有两个:
- 用excel去理解
- 用sql语句去理解
- pandas与numpy的本质区别:
- 是对数据的处理所占的角度不同,这里的excel、sql其实代表着就是各自的思考角度
详细说明:
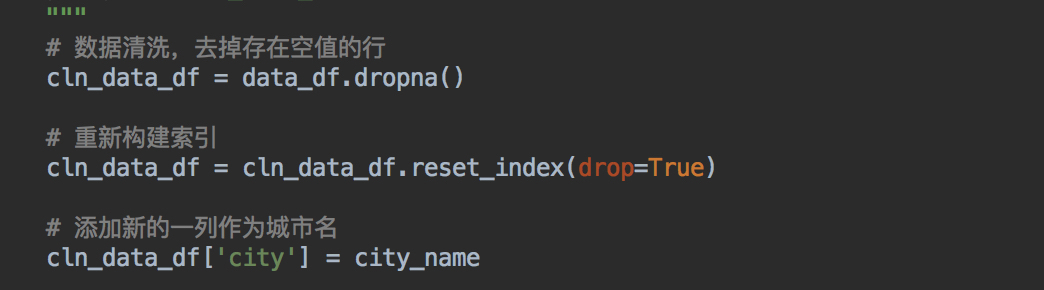
- dropna站在整个表角度进行处理,不用按行进行处理了

- Excle式操作,方便的增加列,操作索引
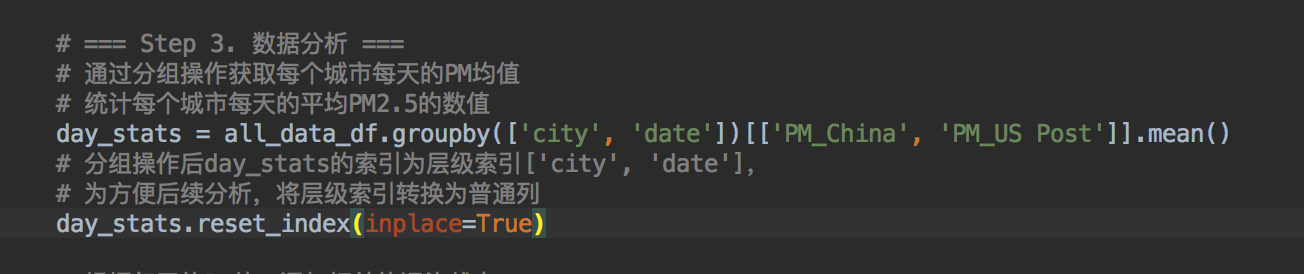
- 向量式的操作方式,类似于sql语句的高级语法,将for循环使用groupby cut等这类操作代替

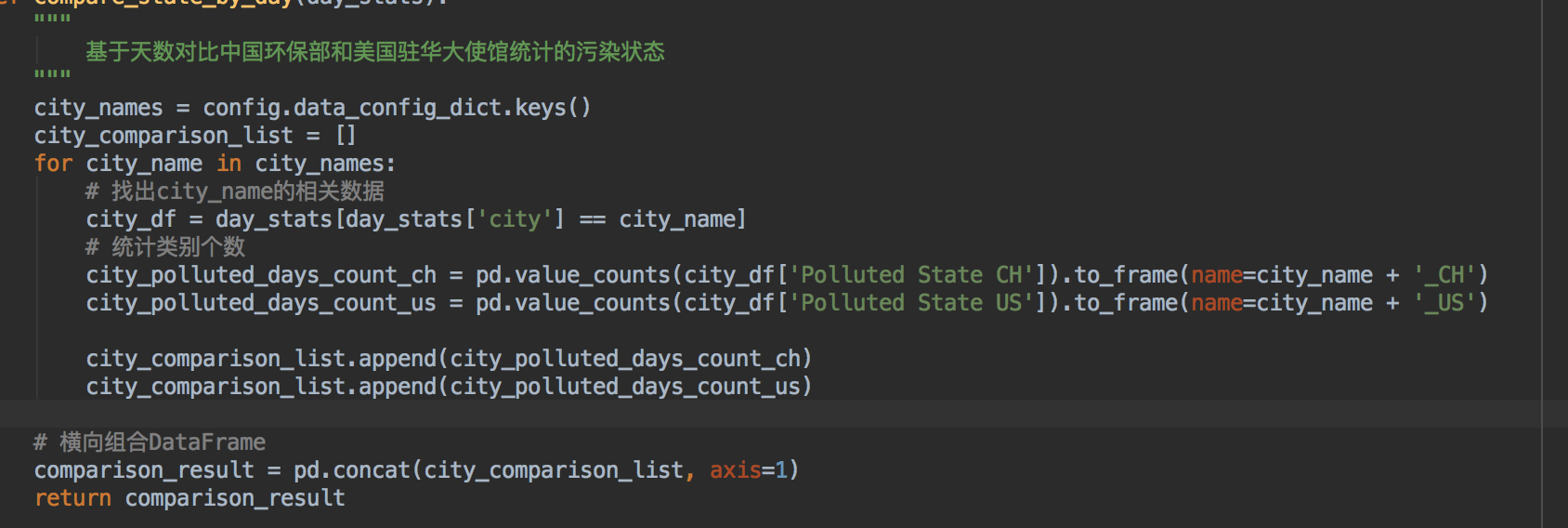
- 依然延续了numpy常用的中的mask操作
- 依然延续了numpy的向量化思维,以行、列作为处理的对象,而不是元素