2018年3月5日 下午11:43
我这里虽然只是罗列了一下知识点,学习的方式主要还是看html
主要内容:
lect02_eg01.html
主要讲解pandas的内容:
- Series
- 创建
- 处理缺失数据
- 索引
- 向量化操作
- DataFrame
- 创建
- 索引
- 删除数据
- DataFrame的操作与加载
- 索引:
- boolean Mask
- 层级索引
lect02_eg02.html
主要讲数据清洗:
- 判断数据缺失
- 处理数据缺失
- 处理重复数据
- 判断数据是否重复,duplicated()
- 去除重复数据,drop_duplicates(),可指定列及如何保留数据
- 使用函数或map转化数据,通常根据字典进行数据转化
- 替换值,replace()
- 离散化和分箱操作,pd.cut(),返回Categorical对象
- 哑变量操作,pd.get_dummies()
- 向量化字符串操作
- 字符串列元素中是否包含子字符串,ser_obj.str.contains()
- 字符串列切片操作,ser_obj.str[a:b]
lect02_eg03.html
合并与分组:
- GroupBy对象:DataFrameGroupBy,SeriesGroupBy
- GroupBy对象没有进行实际运算,只是包含分组的中间数据
- 对GroupBy对象进行分组运算/多重分组运算,如mean()
- 非数值数据不进行分组运算
- size() 返回每个分组的元素个数
- 按列名分组,obj.groupby(‘label’)
- 按列名多层分组,obj.groupby([‘label1’, ‘label2’])->多层dataframe
- 按自定义的函数分组
- 如果自定义函数,操作针对的是index
- 实际项目中,通常可以先人为构造出一个分组列,然后再进行groupby
- GroupBy对象支持迭代操作
- 每次迭代返回一个元组 (group_name, group_data)
- 可用于分组数据的具体运算
- 聚合 (aggregation)
- grouped.agg(func),数组产生标量的过程,如mean()、count()等
- 常用于对分组后的数据进行计算
- 内置的聚合函数:sum(), mean(), max(), min(), count(), size(), describe()
- 可通过字典为每个列指定不同的操作方法
- 可自定义函数,传入agg方法中
lect02_eg04.html
透视表:
- excle说明:
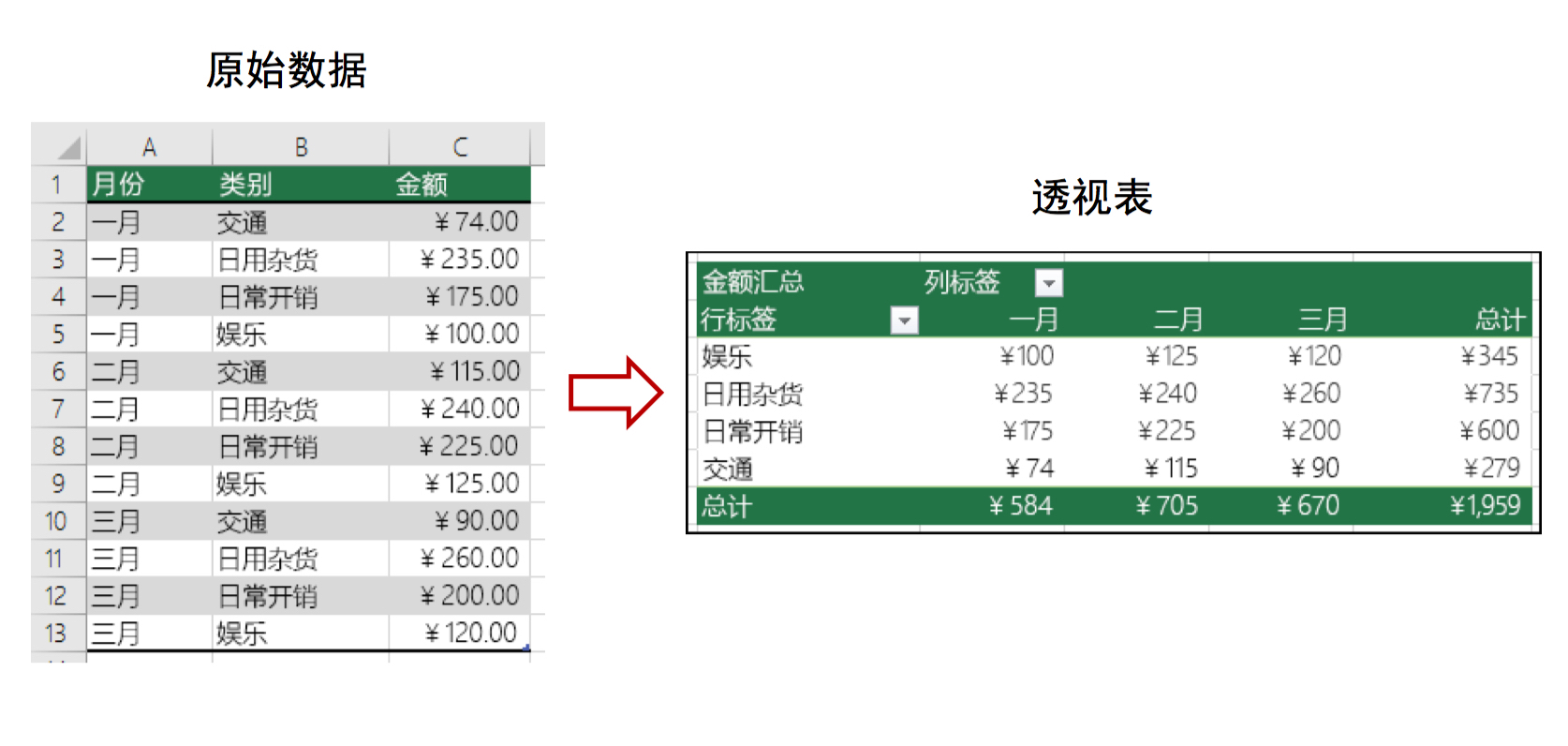
- df.pivot_table(values, index, columns, aggfunc, margins)
- values: 透视表中的元素值(根据聚合函数得出的)
- index:透视表的行索引
- columns:透视表的列索引
- aggfunc:聚合函数,可以指定多个函数
- margins:表示是否对所有数据进行统计
课堂随笔:
drop
copy =
Excel自动转换
Numpy默认全是字符串
广播:mask 列增加
分割
没有index header=0
pandas对缺失值得处理更好
字典型
dropna扔一行
padas取出的value就是numpy
axis
map
一道题