2019年4月28日 下午12:58
深度学习的发展:
- 人工智能研究的方向之一, 是以所谓 “专家系统” 为代表的, 用大量 “如果-就” (If - Then) 规则定义的, 自上而下的思路.
- 人工神经网络 ( Artifical Neural Network),标志着另外一种,自下而上的思路.
- 一个计算模型,要划分为神经网络,通常需要大量彼此连接的节点 (也称 ‘神经元’),并且具备两个特性:
- 每个神经元, 通过某种特定的输出函数 (也叫激励函数 activation function),计算处理来自其它相邻神经元的加权输入值.
- 神经元之间的信息传递的强度,用所谓加权值来定义,算法会不断自我学习,调整这个加权值.
- 学习的就是这个信息传递的强度
- 在此基础上,神经网络的计算模型, 依靠大量的数据来训练, 还需要:
- 成本函数 (cost function)
- 用来定量评估根据特定输入值, 计算出来的输出结果,离正确值有多远,结果有多靠谱.
- 学习的算法 ( learning algorithm )
- 这是根据成本函数的结果, 自学, 纠错, 最快地找到神经元之间最优化的加权值.
- 成本函数 (cost function)
- 用小明,小红和隔壁老王们都可以听懂的语言来解释, 神经网络算法的核心就是
计算, 连接, 评估, 纠错, 疯狂培训
- 分布式表征 (Distributed Representation), 是神经网络研究的一个核心思想.
- 大脑对于事物和概念的记忆, 不是存储在某个单一的地点,而是像全息照片一样, 分布式地, 存在于一个巨大的神经元的网络里.
- 它的意思是,当你表达一个概念的时候,不是用单个神经元,一对一地存储定义; 概念和神经元是多对多的关系: 一个概念可以用多个神经元共同定义表达, 同时一个神经元也可以参与多个不同概念的表达.
- 举个最简单的例子, 一辆 “大白卡车”,如果分布式地表达,一个神经元代表大小,一个神经元代表颜色,第三个神经元代表车的类别. 三个神经元同时激活时,就可以准确描述我们要表达的物体.
- 分布式表征,和传统的局部表征 (localized representation) 相比,存储效率高很多. 线性增加的神经元数目,可以表达指数级增加的大量不同概念.
- 分布式表征的另一个优点是,即使局部出现硬件故障,信息的表达不会受到根本性的破坏.
- 大脑对于事物和概念的记忆, 不是存储在某个单一的地点,而是像全息照片一样, 分布式地, 存在于一个巨大的神经元的网络里.
- 反向传播算法
- 传统的感知器用所谓 “梯度下降”的算法纠错时,耗费的计算量,和神经元数目的平方成正比.
- 1986年七月, Hinton 和 David Rumelhart 合作在自然杂志上发表论文, “Learning Representations by Back-propagating errors”, 第一次系统简洁地阐述,反向传播算法在神经网络模型上的应用.
- 反向传播算法,把纠错的运算量, 下降到只和神经元数目本身成正比.
- 反向传播算法,通过在神经网络里增加一个所谓隐层 (hidden layer), 同时也解决了感知器无法解决异或门 (XOR gate) 的难题.
- 支持向量机 (Support Vector Machine)
- 早在1963年, Vapnik 就提出了 支持向量机 (Support Vector Machine) 的算法.支持向量机, 是一种精巧的分类算法.
- 除了基本的线性分类外,在数据样本线性不可分的时候, SVM 使用所谓 “核机制” (kernel trick) 的非线性映射算法, 将线性不可分的样本转化到高维特征空间 (high-dimensional feature space),使其线性可分.
- Vapnik 的观点是, SVM,非常精巧地在 “容量调节” (Capacity Control)上 选择一个合适的平衡点, 而这是神经网络不擅长的.
- 什么是 “容量调节”?
- 举个简单的例子: 如果算法容量太大,就像一个记忆力极为精准的植物学家, 当她看到一颗新的树的时候,由于这棵树的叶子和她以前看到的树的叶子数目不一样,所以她判断这不是树; 如果算法容量太小,就像一个懒惰的植物学家,只要看到绿色的东西,都把它叫做树.
- 严乐春的观点是, 用有限的计算能力,解决高度复杂的问题,比”容量调节”更重要. 支持向量机,虽然算法精巧,但本质就是一个双层神经网络系统.它的最大的局限性,在于其”核机制”的选择 . 当图像识别技术需要忽略一些噪音信号时,卷积神经网络的技术,计算效率就比 SVM 高的多.
- 神经网络的计算,在实践中还有另外两个主要问题:
- 第一, 算法经常停止于局部最优解,而不是全球最优解. 这好比”只见树木,不见森林”.
- 第二, 算法的培训,时间过长时,会出现过度拟合 (overfit),把噪音当做有效信号.
- 有哲人对蛮力有另外一个诠释: “Quantity is Quality”.
- 主流学术界的研究者,大多注重于在算法上的渐进式提高, 而轻视计算速度和用于训练的数据规模的重要性.
- 从生存所需的能量角度去理解能量函数:
- 神经网络的模型中,通过所谓激励函数 (activation function), 根据上一层神经元输入值来计算输出值
- 最典型的传统激励函数,sigmoid function, 输出值在 0 和 1 之间, 也就意味着神经元平均下来, 每时每刻都在使用一半的力量.
- RELU
- 2011 年, 加拿大的蒙特利尔大学Yoshua Bengio
- 解决 过度拟合 (overfitting).
- 2012年七月, Hinton 教授一种新的称为”丢弃” (Dropout) 的算法.
- 丢弃算法的具体实施,是在每次培训中, 给每个神经元一定的几率 (比如 50%),假装它不存在,计算中忽略不计.
- 从一个角度看, 丢弃算法,每次训练时使用的是不同架构的神经网络 (因为每次都有部分神经元装死),最后训练出来的东西,相当于不同架构的神经网络模型的平均值.
- 从生物的有性繁殖角度看,丢弃算法,试图训练不同的小部分神经元,通过多种可能的交配组合,获得接近理想值的答案.
- 2012年七月, Hinton 教授一种新的称为”丢弃” (Dropout) 的算法.
- 2012年,Hinton 教授和他的两个研究生 Alex Krizhevsky, Illya Sutskever 将深度学习的最新技术用到 ImageNet 的问题上.
深度学习有多深?学了究竟有几分?(九) - Hinton 教授的父亲 Howard Hinton
深度学习有多深?学了究竟有几分?(十) - 2015何凯明,深度残余学习”的概念, 借鉴了图像识别中的”残余向量”的概念.
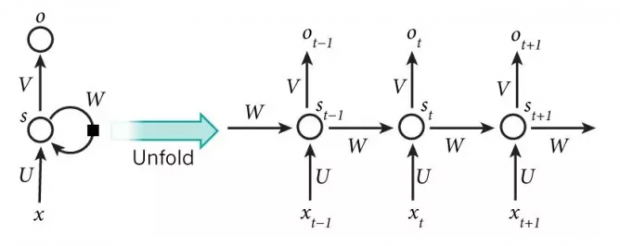
- 迄今为止我们讨论的神经网络模型, 都属于一种叫做前馈网络 (feedforward network) 的东西. 简而言之, 前馈网络, 信息从底层不断往前单向传输,故而得名.
- RNN
- RNN (Recurrent Neural Network), 也称循环神经网络, 多层反馈神经网络, 则是另一类非常重要的神经网络.
- 本质上, RNN 和前馈网络的区别是,:它可以保留一个内存状态的记忆, 来处理一个序列的输入, 这对手写字的识别, 语音识别和自然语言处理上, 尤为重要.
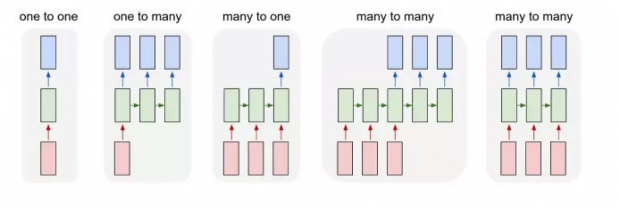
- 从另外一个角度看, 传统神经网络, 输入和输出的向量, 长度都是固定的, 是简单的一对一的关系.
- 1997,LSTM
- 如果”忘记历史意味着背叛”, 那么对于没有使用 LSTM 的神经网络, “忘记历史则意味着迷茫和不知所措”。”深度残余学习”, 本质上是借鉴了 LSTM 模型的思路, 但是去掉了里面的 forget gate (遗忘之门) 这个概念而已.
自然语言:
- 马尔科夫模型
- 马尔科夫模型, 是一个概率的模型. 其核心思想, 就是一个系统, 下一个时间点的状态, 只取决于当前的状态, 而和更早的时间点 (昨天, 前天, 大前天)的状态无关.
- 高斯混合模型
- 就是把现实中的数据, 分解成一些基于高斯概率密度函数 (又称正态分布)的叠加
- 高斯混合模型的硬伤,
- 是在部分应用场景中, 试图用过于复杂的统计模型,拟合本质上很简单的数据
深度学习有多深?学了究竟有几分?(十三)
- 是在部分应用场景中, 试图用过于复杂的统计模型,拟合本质上很简单的数据
- 2015年五月, 谷歌宣布, 依靠 RNN/LSTM 相关的技术, 谷歌语音 (Google Voice) 的单词错误率降到了8% (正常人大约 4%).
深度学习有多深?(十四)循环神经网络和言情小说 - 循环神经网络 (RNN)的本质,
- 是可以处理一个长度变化的序列的输出和输入 (多对多). 广义的看, 如果传统的前馈神经网络做的事, 是对一个函数的优化 (比如图像识别). 那么循环神经网络做的事, 则是对一个程序的优化,应用空间宽阔得多.
- 长短期记忆 (LSTM)的架构, 使有用的历史信息, 可以保留下来,很久以后仍然可以读取.
深度学习有多深?(十五)自然语言的困惑