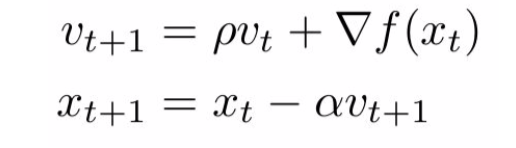2019年5月29日 下午9:44
Avoiding and Identifying False Sharing Among Threads | Intel® Software
网页( https://software.intel.com/en-us/articles/avoiding-and-identifying-false-sharing-among-threads ) 是intel的官网重点讲解了cache line的问题。本质来说就是由于cache的引入导致了数据的不唯一化,那么多数据时间的同步就会让并行的效率有所下降。解决方案就是使用线程的局部数组,_不再操作同一片内存区域,而不是不同的线程操作不同的区域_。正如代码中所描述的:Note that this program avoids the false sharing problem by storing partial sums into a private scalar.


/%E5%B7%A5%E7%A8%8B/%E8%BF%90%E8%A1%8CPolyFit%E4%BB%A3%E7%A0%81%EF%BC%9A%E6%9C%AA%E5%A3%B0%E6%98%8E+%E4%BB%A3%E7%A0%81%E4%BF%AE%E6%94%B9/PolyFit.PNG)