2019年1月22日 下午12:31
提高自己阅读论文效率的技巧:
- 一定要拿上张纸写自己在阅读过程中的思考
- 让自己办事的时候思路清晰
- 简单但是却十分的关键
- 阅读论文一定要明确自己的问题
- 这也是让自己思路清晰的手段,每阅读一段话,都要有清晰的目的,知道自己要干什么、缺什么
- eg:
- 我对当前知识的一个推理
- 定位相关内容,并验证
- 做出自己的判断和理解
2019年1月18日 下午12:21
OpenCV闯关记——Ubuntu16.04 OpenCV Python开发环境搭建 - 小杰控的清水道场 - SegmentFault 思否
1 | sudo apt-get install build-essential cmake pkg-config |
2019年1月17日 下午4:00
2019年1月13日 下午4:00





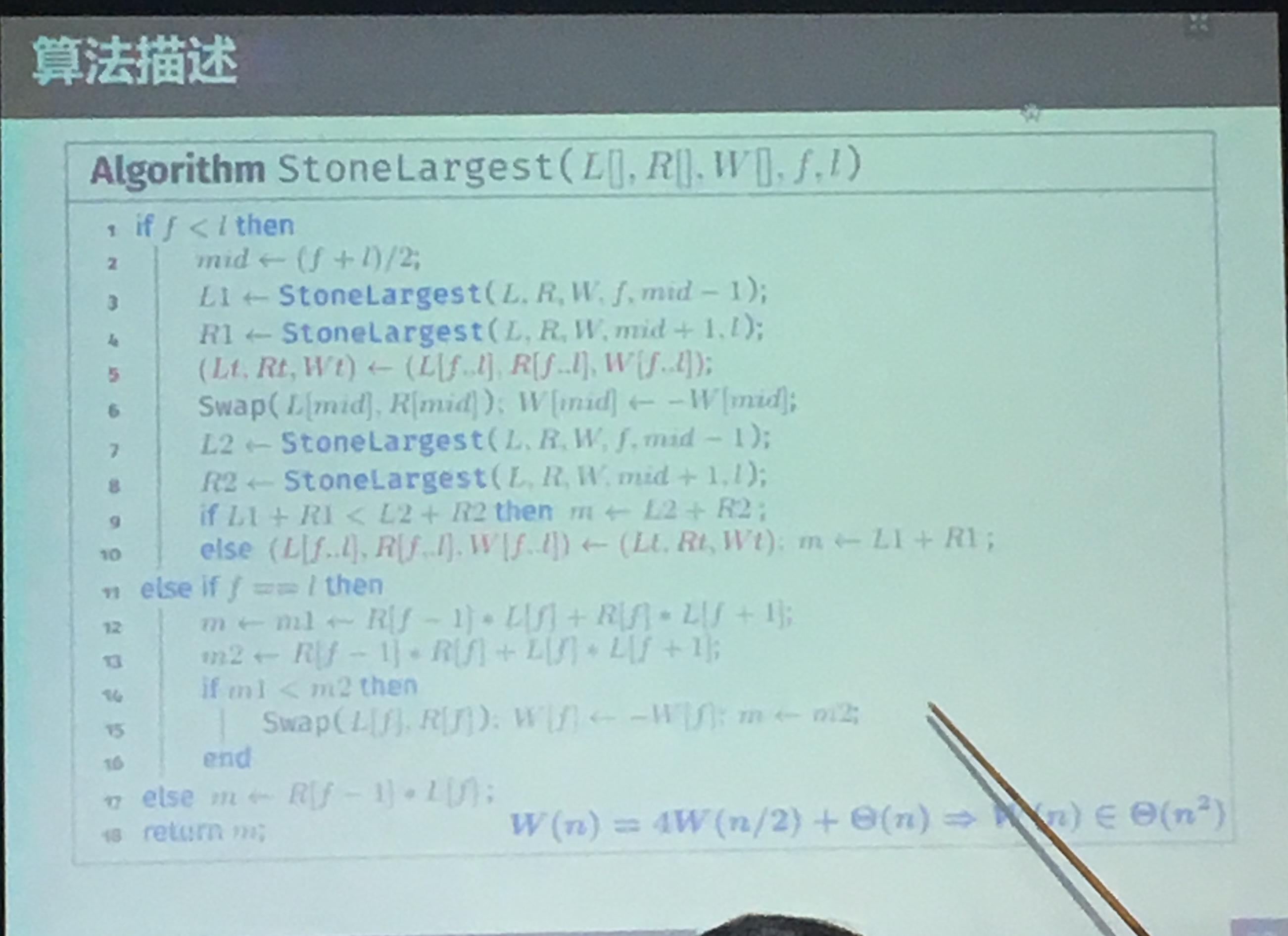


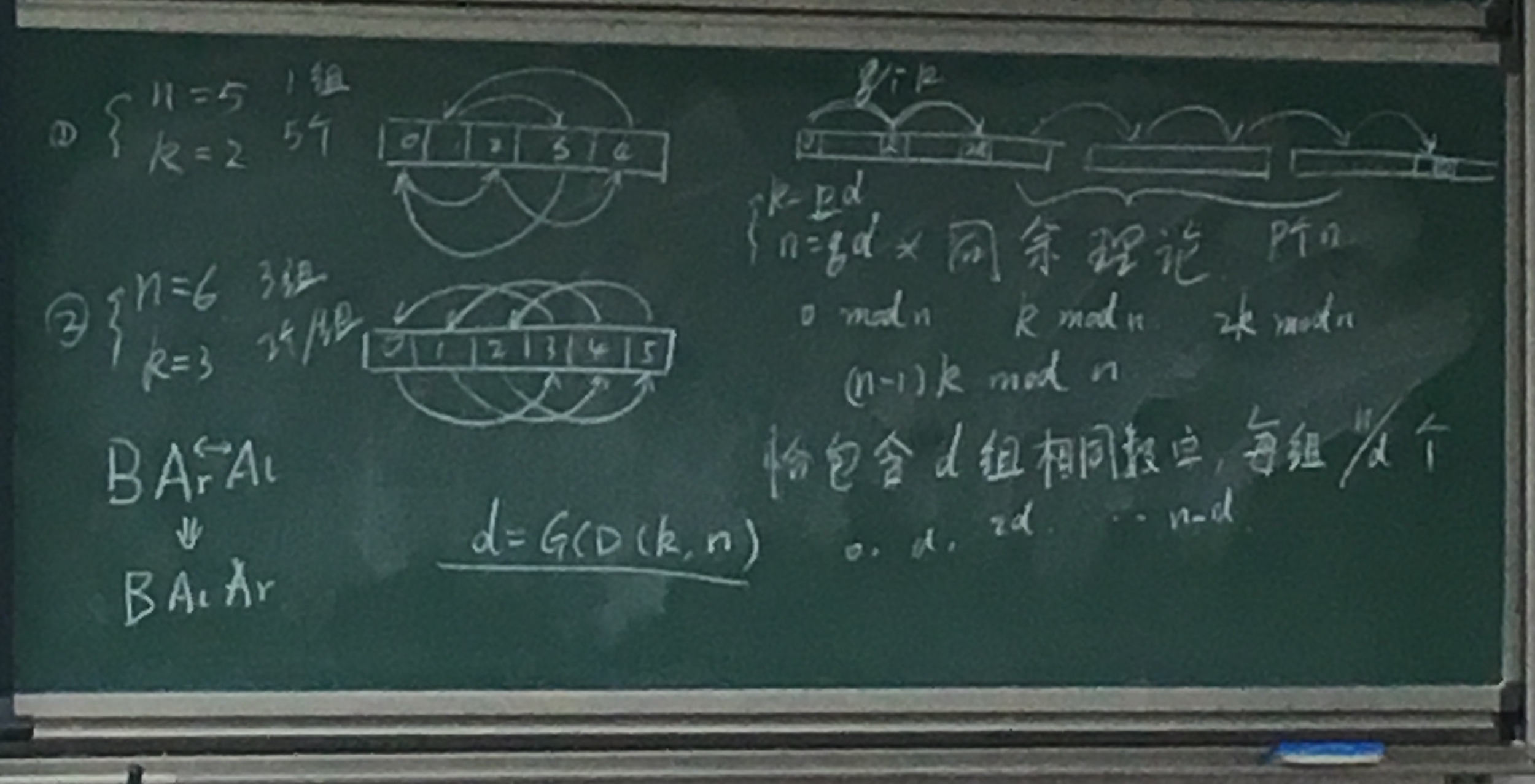
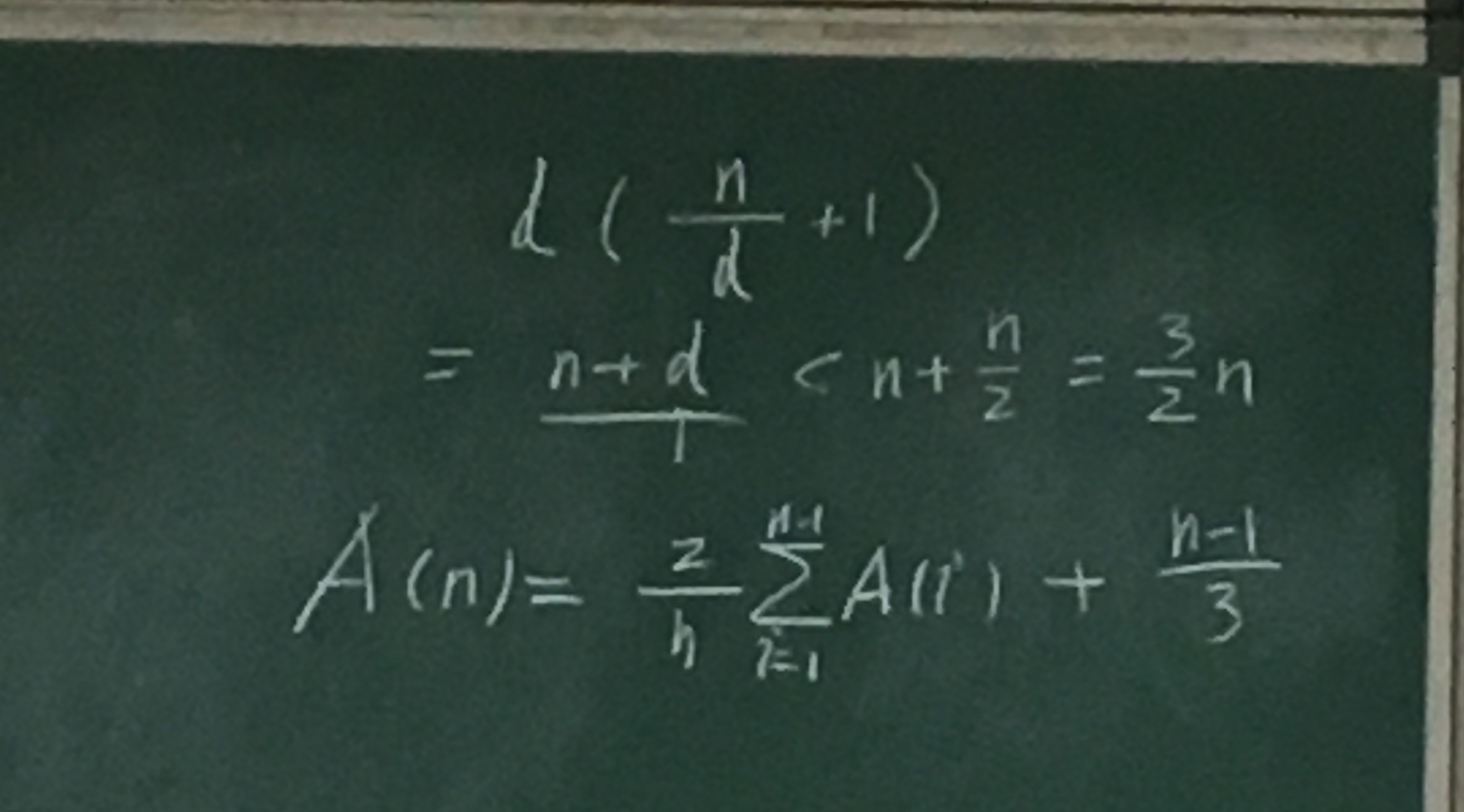


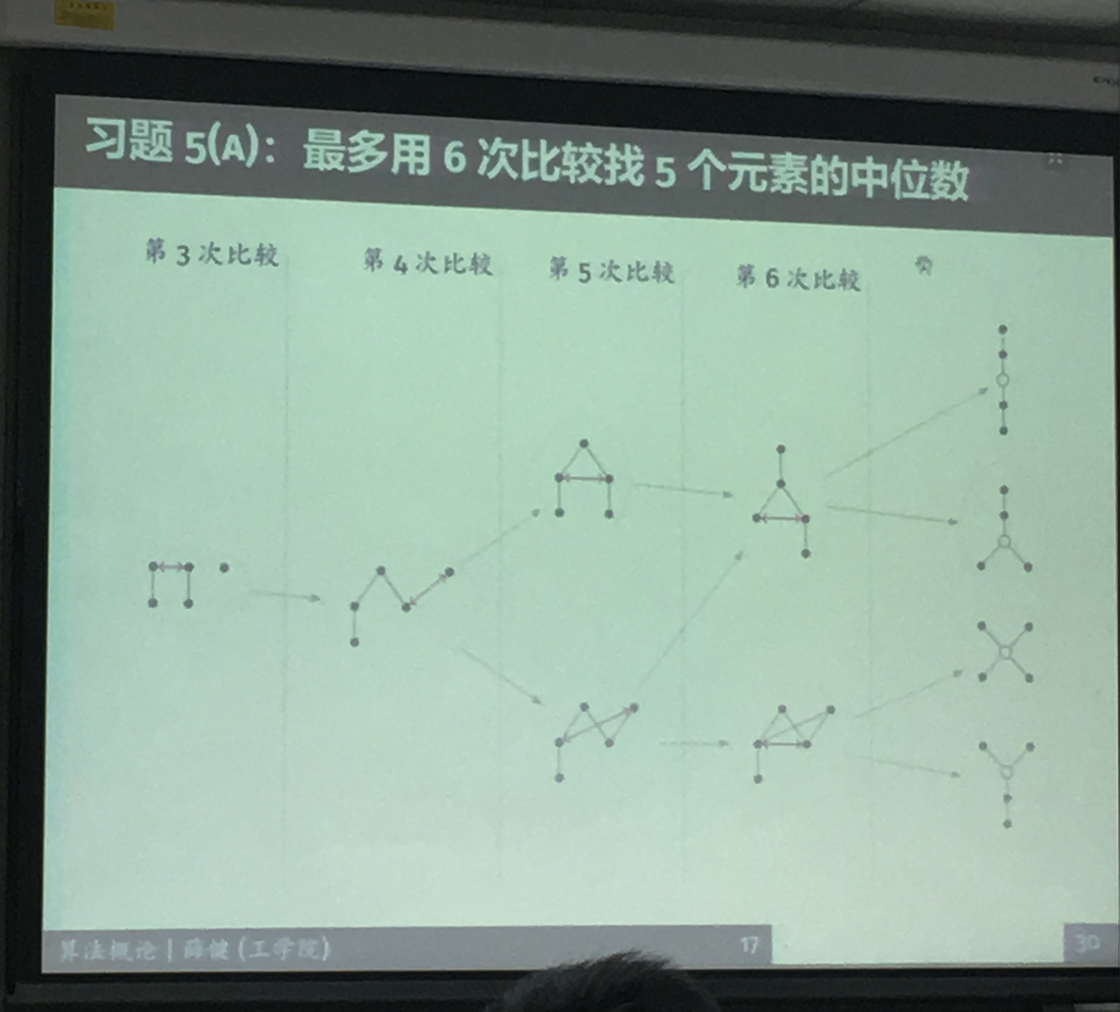
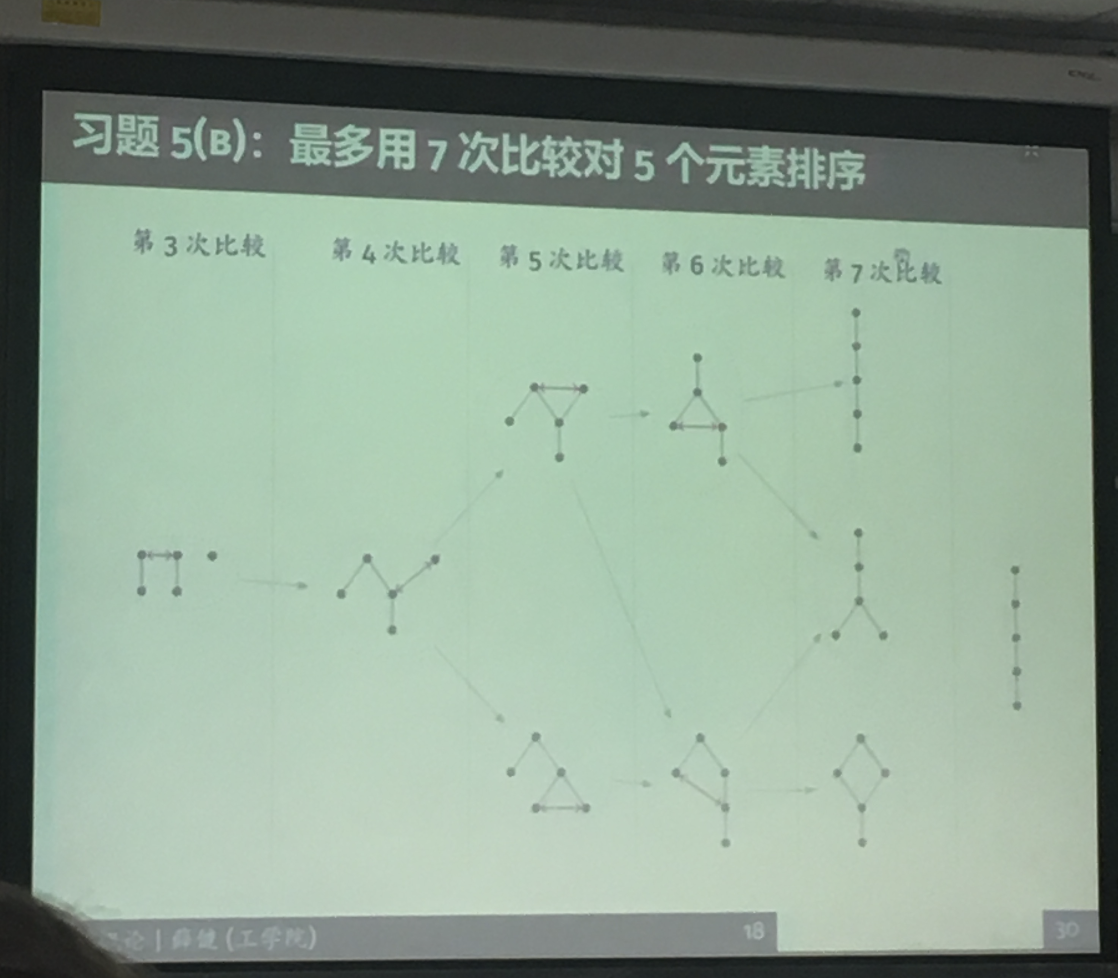






2019年1月11日 下午3:02
2019年1月10日 下午3:19
KCF跟踪算法c++-CSDN下载c++版
João F. Henriques官方
好文章我已近打印出来看:
其他:
KCF目标跟踪方法分析与总结 - 一只有恒心的小菜鸟 - 博客园
KCF相关滤波跟踪算法 - 知乎
公式推导:【CFNet//CVPR2017】 - 博闻强记2010 - 博客园
CFNet视频目标跟踪核心源码分析——网络结构设计及实现
2019年1月10日 下午3:09
别站在为了使用某个知识点的角度去思考,而是要反过来从问题来找可以解决的知识点或者思路

2019年1月10日 下午3:07
2019年1月10日 下午2:56
我这里只是列出一些其中的关键词


