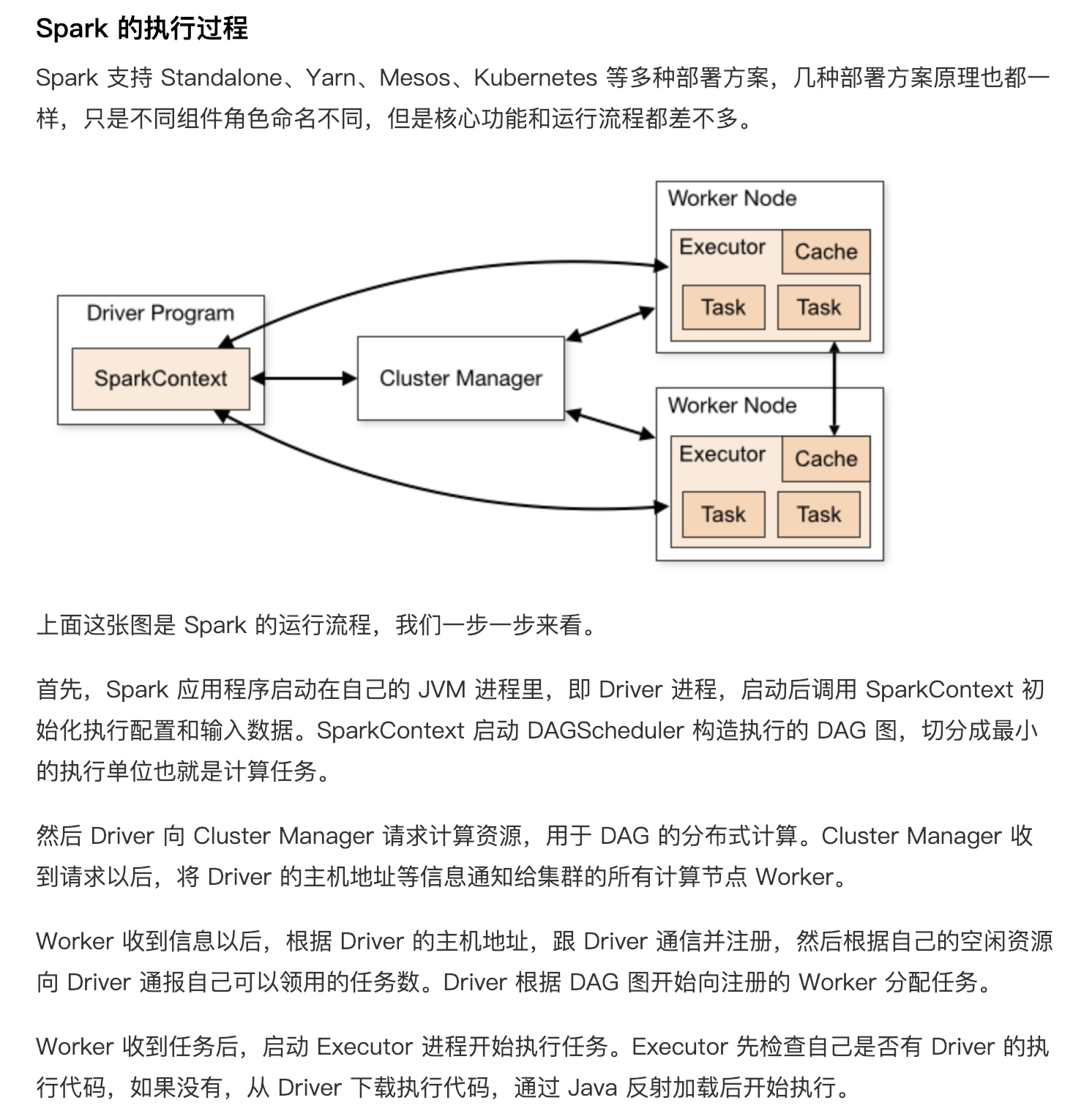
2019年1月2日 上午10:29
OpenCV
Ubuntu 16.04 安装opencv的各种方法(含opencv contrib扩展包安装方法) - ZeroZone零域的博客 - CSDN博客
测试:
OpenCV+Ubuntu18.04环境搭建 - qq_38660394的博客 - CSDN博客
QT
主要:
Ubuntu 16.04上安装QT - Hansion的博客 - CSDN博客
ubuntu16.04设置Qt环境变量 - 大黄老鼠的博客 - CSDN博客
次要:
在Ubuntu下安装qt - Welcome you, my friend - CSDN博客
测试:
在Ubuntu下搭建Qt开发环境和Qt creator - 花花的博客 - CSDN博客
/mve/MVE%E4%BB%A3%E7%A0%81%E8%BF%90%E8%A1%8C%E7%AC%94%E8%AE%B0/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-12-31%20%E4%B8%8B%E5%8D%889.00.32.png)
/mve/MVE%E4%BB%A3%E7%A0%81%E8%BF%90%E8%A1%8C%E7%AC%94%E8%AE%B0/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-12-31%20%E4%B8%8B%E5%8D%888.38.37.png)
/mve/MVE%E4%BB%A3%E7%A0%81%E8%BF%90%E8%A1%8C%E7%AC%94%E8%AE%B0/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-12-31%20%E4%B8%8B%E5%8D%888.41.43.png)
/mve/MVE%E4%BB%A3%E7%A0%81%E8%BF%90%E8%A1%8C%E7%AC%94%E8%AE%B0/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-12-31%20%E4%B8%8B%E5%8D%888.43.56.png)
/mve/MVE%E4%BB%A3%E7%A0%81%E8%BF%90%E8%A1%8C%E7%AC%94%E8%AE%B0/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-12-31%20%E4%B8%8B%E5%8D%888.50.24.png)