2018年12月29日 下午1:04
心得
2018年12月28日 下午1:46
full-field shape
全视野(12)
experimental mechanics
实验力学
stereovision
立体视觉(502)
optical bandpass filter
光学带通滤波器
笔记要围绕这几个点进行:
- 自己的要解决的问题
- 这点非常重要,因为他是你阅读效率的保证
- 新的概念
- 新的流程:流程一般都会配图,否则很快就会忘记论文内容,白看
- 引用的很多论文,其实大的流程都没有变,只是在其中更换了、或添加了一些方法、基础数据等等。
- 最后导致,introduction比他自己的方法对我来说更有用。
阅读论文的整体感觉就像是:不断的名词解释,而且英语的语法便于做这样的事情。按着这样的思路,阅读速度也会加快
VIC - 3D-北京睿拓时创科技有限公司
VIC-3D非接触全场应变测量系统
相关产品:
Digital Image Correlation (DIC) Measurement Systems
Q400 - Digital Image Correlation
3D Digital Image Correlation System Q-400 - EZ-mat, Solutions for material testing
MultiDIC: An Open-Source Toolbox for Multi-View 3D Digital Image Correlation — MIT Media Lab
3D DIC
2018年12月27日 上午9:45
无接触式监测.pdf
视场_百度百科
三维位移
摄影基础教学——光圈快门ISO - YouTube
光圈、快門、ISO 基本概念(上篇) - YouTube
控制照片的曝光(亮暗)
摄影世界入门 - YouTube
DIC 数字图像相关原理 - ACQTEC 研索仪器 VIC-3D vic3d DIC 数字图像相关 非接触全场 Psylotech µTS 介观尺度 shearography 复合材料缺陷检测
- 三维重建涉及的是变形过程中的多个状态,每个状态包含左右2幅图像。如图5所示,整个相关匹配过程中,所有状态的左图像都以状态1(未变形状态)的左图像为参考图像进行相关匹配,所有状态的右图像都以该状态的左图像为参考图像进行相关匹配。匹配完毕后,对于任意一个状态的左右两幅图像,利用标定得到的摄像机内、外参数,按照三角测量原理就可以重建对应的三维点坐标。
- 摄像机的标定是指确定其内、外方位参数的过程。如前所述,传统的像机标定通常都需要利用高精度的标定板, 通过标定块已知的三维点的坐标与对应的图像点坐标的关系来计算像机的内、外参数 ,因此标定块的制作误差会导致标定精度的下降。基于摄影测量方法的摄像机标定方法不需要高精度的标定板,只需要将标定板上任意一对标识点的准确距离作为比例尺就可以准确地计算出摄像机的内、外方位参数。
- 2按照5.1节的方法将所有状态进行三维重建后,以状态1作为参考状态,变形过程中任意一个状态的三维点坐标减去参考状态的三维点坐标就得到该状态的三维位移。
/dic/3D%20DIC/D56BCD02-878E-4220-879E-58091075762F.png)
地震振动台实验三维全场位移测量的研究/dic/3D%20DIC/8380FB5E-B2C3-4854-A106-37C5D74513CB.png)
本文的实验系统硬件主要由高性能电脑、测头、强光源、三脚架、1.5 m×1.5 m标定十字架组成。测头(如图3)由Basler工业相机、焦距为351Tlnl的施耐德镜头以及横梁组成。相机芯片像素分辨率为2 048 pixel*1 088 pixel,模型具体尺寸3 000 mm×I 500 mm×1 300 mm。/dic/3D%20DIC/F924C105-2941-45C1-A42C-1819BB8A6F95.png)
/dic/3D%20DIC/D7DF47A5-A799-4986-8E39-CC73456FF476.png)
VDI/VDE 2634 是德国联邦物理研究院于2002年制定的关于工业测量领域的规范http://www.chinamtt.cn/Upload/2015-07/20150703.pdf
Two-dimensional digital image correlation for in-plane displacement and strain measurement: a review:2009
Web of Science v.5.31 - 所有数据库 全记录
Color Stereo-Digital Image Correlation Method Using a Single 3CCD Color Camera:2017
Web of Science v.5.31 - 所有数据库 全记录
- Stereo-digital image correlation (stereo-DIC, also termed as 3D–DIC)
- random speckle patterns
/dic/3D%20DIC/27C204FD-3E2B-4EBA-A2BE-8880338D4279.png)
/dic/3D%20DIC/9FD8A135-40F6-47D7-A6B3-B4A0014BDAC4.png)
/dic/3D%20DIC/B3ADC158-7D70-40CA-A092-9C4A8CD233C4.png)
/dic/3D%20DIC/31A41868-9CDA-4B71-8F31-5D278794C0F5.png)
Full-field 3D measurement using multi-camera digital image correlation system - ScienceDirect/dic/3D%20DIC/3F8959DB-18CB-4713-8D28-D08FFBC89897.png)
/dic/3D%20DIC/B969865C-10F0-462F-92A2-FC256A6870F0.png)
/dic/3D%20DIC/FF362AB1-152D-46AE-8F1F-6A0C1CB68E13.png)
/dic/3D%20DIC/FB83C379-58D5-476E-91CD-10AD3864A173.png)
/dic/3D%20DIC/544C2756-F591-42E1-A3DF-855CA4120A8A.png)
数字图像相关(中文论文)
2018年12月24日 下午12:05
数字图像相关(DIC)测量方法在材料变形研究中的应用_百度学术
数字图像相关(Digital Image Correlation)测量技术是应用计算机视觉技术的一种图像测量方法,是一种非接触的、用于全场形状、变形、运动测量的方法。它直接处理的对象是具有一定灰度分布的数字图像(散斑图),通过对比材料或者结构表面在变形前后的散斑图运用相关算法得到全场位移和应变。
三维数字图像相关法及其在水泥基材料变形研究中的应用_百度学术
- 三维数字图像相关法(three-dimensional digital image correlation,3D-DIC)又称三维数字散斑相关法(threedimensional digital speckle correlation method,3D-DSCM),是一种新型的非接触式全场光学测量方法。
- 数字图像相关法是一种通过记录和分析物体表面随机分布的散斑在物体变形前后的系统相关性,来计算物体表面形变的一种光学测量技术
- 与比长仪等传统方法相比,三维数字图像相关法具有测量精度高,可准确测量物体表面的三维形貌和变形等优点。
- 本文介绍了三维数字图像相关法的基本原理、关键技术和精度分析等,并结合水泥基材料的特点,讨论了三维数字图像相关法在水泥基材料变形研究中的应用。
三维数字图像相关技术(3D DIC)在材料形变研究中的应用进展_百度学术
指出在散斑对测量精度影响、微应变尺度测量、环境因素对测量效果干扰
散斑图像:
基于激光散斑图像的目标识别研究
介绍了散斑的成像原理,特性
散斑图像相关数字技术原理及应用
散斑图是通过CCD照相机生成的
基本方法流程:
- 利用线阵CCD具有实时传输光电变换信号和自扫描速度快、频率响应高、能够实现动态测量以及价格低廉等特点,选择线阵CCD采集散斑图像;利用FPGA并行处理数据速度快这一优势,CCD输出信号通过信号调理电路后经A/D转换送入FPGA进行相关运算,最终通过散斑图像的位移量来获得目标角振动信息;用MATLAB软件编程来实现对测量系统的理论仿真及结果验证。
散斑:
- 散斑的形成的物理原理
- 数字散斑相关方法(DSCM)的基本原理
CCD简介:
- CCD 的工作原理是将目标或光源入射到 CCD 光敏面上的光强分布信息通过光电转换原理转变为电荷量信息,并且按照一定的时序(脉冲信号)将临时存放在寄存器中的电荷量信号移位串行输出,输出的电信号再经过信号调理电路和相关软件的处理后就可再现被测物体的原始信息。
- 从 CCD 器件的结构上来看,可以分为线阵 CCD 和面阵 CCD 两种。
- CCD 器件普遍具有高解析度、低噪声、高灵敏度、动态范围大、线性特性好、转换效率高、光谱响应宽以及体积小、重量轻等优点。
FPGA
- 传统的数字散斑相关方法使用图像采集卡采集散斑图像,并输送至计算机采用 MATLAB 或 C 语言编程进行相关搜索和相关运算,具有运算大、运算速度慢、无法实时动态测量等缺点。
- 本论文提出测量方案选用现场可编程逻辑门阵
列(FPGA)实现相关搜索和相关运算。FPGA 最大的优点在于并行计算特性以及灵活的可重构特性,还可根据具体算法来实现特定的并行处理结构或流水线结构,有更多的处理单元来执行运算,这就极大提高了算法运算速度和处理系统的吞吐量。
【面阵ccd】_面阵ccd品牌/图片/价格_面阵ccd批发_阿里巴巴
http://www.siaon.com/pdf/camera.pdf
视觉测量
标定板
图像式远程目标微小位移监测系统的设计与实现_百度学术
该系统设计的基本思路是使用CCD摄取目标图像,通过监控目标中心在图像中的位置变化实现对远程目标微小位移的准确监测。
地质灾害监测新仪器—激光微小位移监测系统_百度学术
本项研究成果采用了先进的激光技术、CCD摄像技术和微机数字处理技术,对滑坡体的水平位移、垂直位移和轴向位移实现远距离、非接触、全天候、全自动监测,
图像处理技术在地质灾害监测中的应用_百度学术
三维激光微位移监测技术是一种对地质灾害进行长期监测的新方法.该技术用激光作为光源,用CCD摄像器作为镜头,通过图象采集卡把视频信号采入计算机中,用与该仪器配套的专门软件对采集到的光斑图像进行处理,计算出光斑的三维中心坐标值,把该值和原点坐标值进行比较,就可以算出灾害体滑动的距离.该系统可以对灾害体进行长期、非接触监测,监测时间、监测频率可以任意设定.
机器视觉基础知识详解 - 简书
科研相机选择:sCMOS还是CCD? - 知乎
CCD 照相机_百度百科
机器视觉就是用机器代替人眼来做测量和判断。机器视觉系统是通过机器视觉产品(即图像摄取装置,分CMOS和CCD两种)将被摄取目标转换成图像信号,传送给专用的图像处理系统,得到被摄目标的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。
- 基于机器视觉和激光技术的相对位移测量装置有效克服了位移非直线变形的弊病,利用激光成像技术实现了相对位置变形的确定,可以测量灾害体在三维空间上的位移变化量
- 反射后激光光线的接收和对比,以确定位移变化量。激光三维位移测量装置由发射模块和接收模块两部分组成,发射模块主要为带有两个有一定夹角的点激光发射管,在测量时发射两条激光线。接收模块由一块白色PVC板和摄像镜头组成,用来实现
程序单词共现矩阵
2018年12月24日 下午3:54
- wordCount,矩阵乘法:MapReduce 基础算法程序设计(1)-Mapreduce-about云开发
- 关系代数运算:MapReduce 基础算法程序设计(2)-Mapreduce-about云开发
- 单词共现:MapReduce 基础算法程序设计(3):单词共现算法-Mapreduce-about云开发
参考的文章:
MapReduce算法设计-计算单词共现矩阵 - nianyuweiwei的专栏 - CSDN博客
讲原理的文章:
每周学点大数据 | No.39单词共现矩阵计 - 云+社区 - 腾讯云
第三次作业
2018年12月24日 下午3:54
计算单词共现矩阵
开发环境截图:
.png)
执行结果:
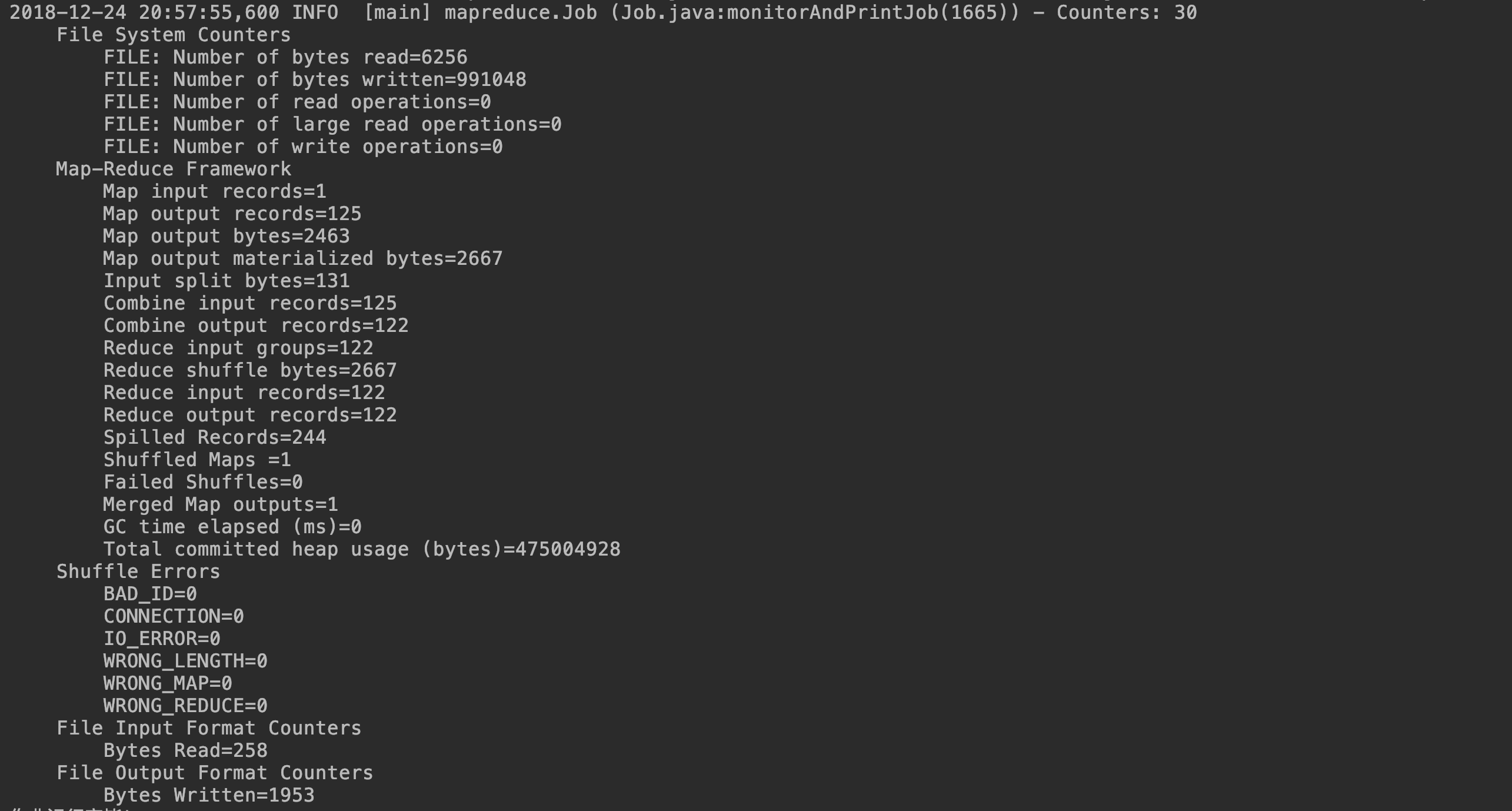
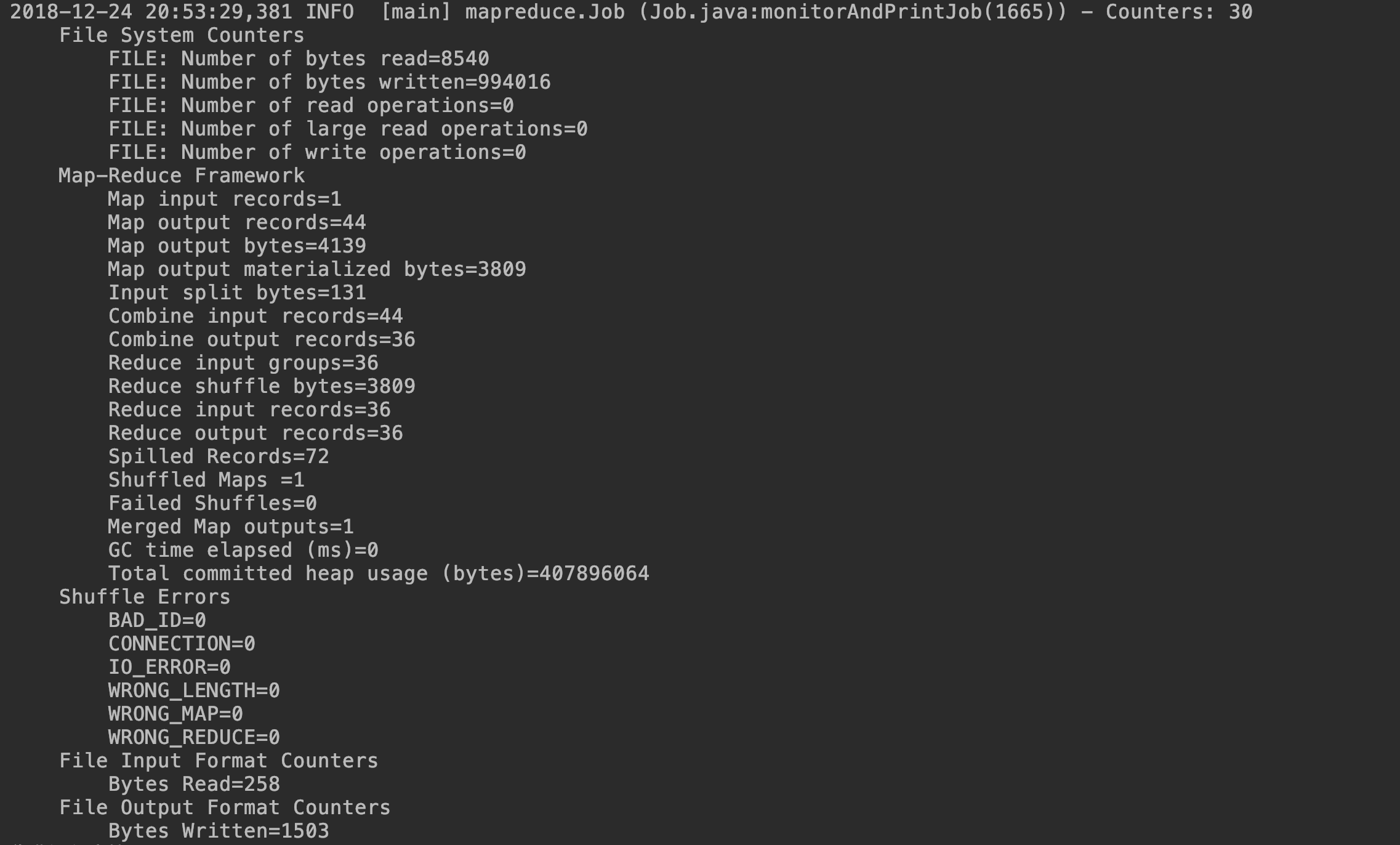
代码
occurrence_matrix.java
1 | package mp.occurrence_matrix; |
TextPair.java
1 | package mp.co_occurrence_matrix; |
TextStripe.java
1 | package mp.co_occurrence_matrix; |
Hive常见的数据导入方式
2018年12月23日 下午3:54
Hive常见的数据导入方式 | Wing’s Tech Space
1 | localhost:~ czh$ hive |
自己造的数据:
hive.txt
hive安装
遇到的错误
环境搭建总结
2018年12月23日 下午3:12
解决问题的思路:
- cmakelist.txt中解决问题
- cmake中一些配置项没有正确的配置
- 依赖环境解决问题
- 典型的是brew install vtk —with-qt
- 编译器解决问题
- 选择正确的编译器
- 所有解决问题的思路都是根据命令行的提示、报错等等。
- 坑:
- 网上的解决方案千奇百怪,有很多都随时间版本的升级而过时了【时间】
- 有些他的解决方案并不针对你电脑的当前环境【针对性】
- 你根据别人的方案解决现有问题时,可能并不能解决当前问题,并且还要引入新的问题。【自己引入新的问题】
- 我使用gcc编译器就是一个典型的例子
- 我们要根据提示+知识推理(计算机系统)去甄别我们的问题
- 在实在误解的情况下,可以尝试顺藤摸瓜,直指源码
- 坑:
正确编译的几个重要模块:
安装—安装对—编译器选对—代码可跨平台