2018年9月11日 下午3:54
A星算法详解(个人认为最详细,最通俗易懂的一个版本) - CSDN博客
- 我无法回答为啥通过这样的迭代方式,就可以产生最终的答案
- 我的理解:
- 算法的目的:能够设计出跳出局部最优解,从而选取全局最优解
- 方法:利用堆栈来记录自己的候选位置,配套设计了一套约束,用来限制下一点的走向。
- 评价函数的定义也是A*算法的难点,相同的问题可以定义不同的评价函数,会有不同的效果

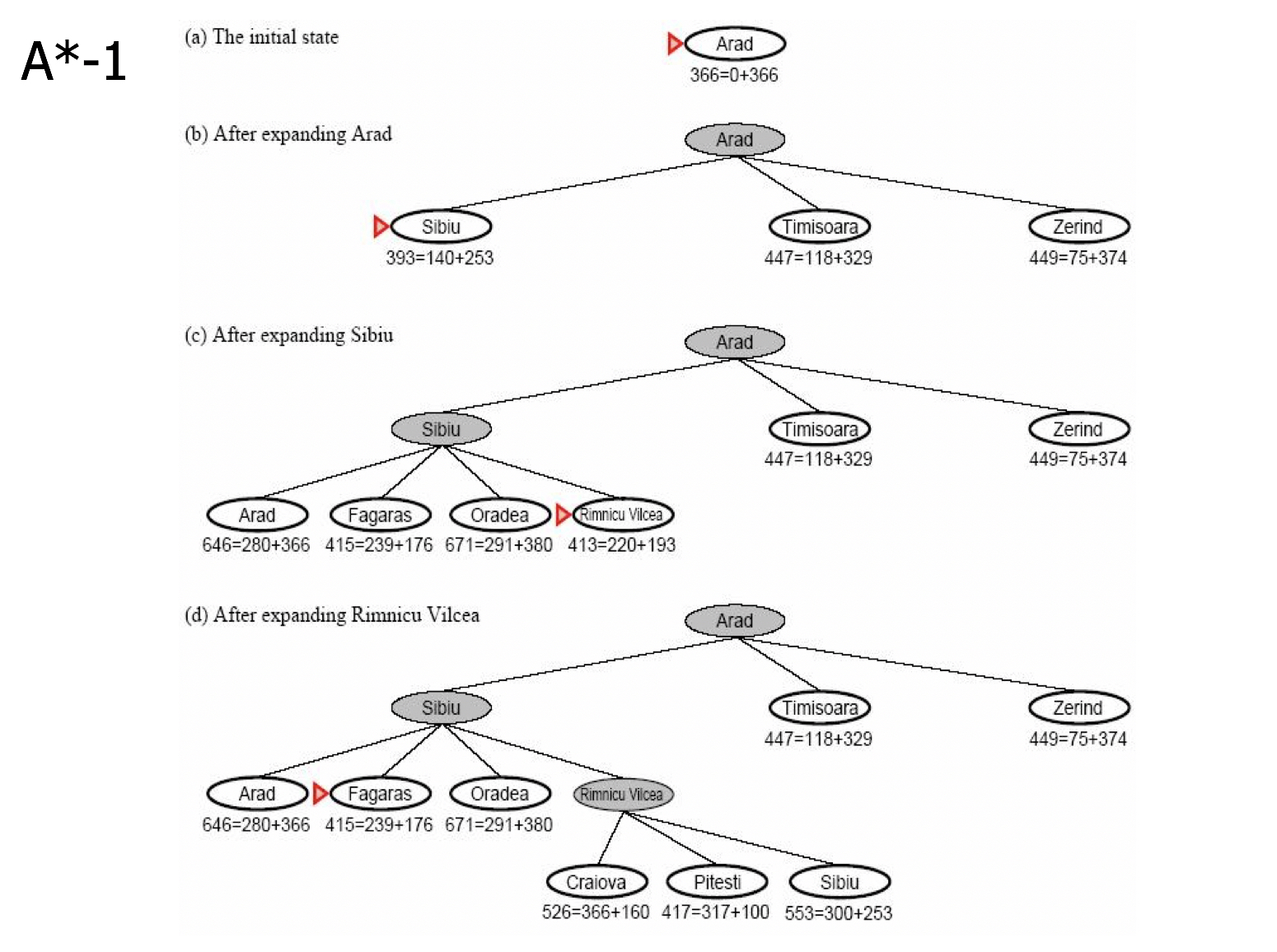
- A*算法在树模型下的处理,不同的模型,不同点在于:寻找下一个点的方式不同,在URL连接中的例子,值寻找当前点周围的满足要求的8个点,而树中是寻找子节点。同样也会有堆栈来保存候选点这些概念。总结来说:不同点就是在某个大致的动作中,换了一些具体的操作行为。

/%E5%B7%A5%E5%85%B7/C++%20%E7%B1%BB%E8%AE%BF%E9%97%AE%E6%8E%A7%E5%88%B6/B7AFCE3C-7D9C-4758-BB25-A8E2014F216F.png)
/%E5%B7%A5%E5%85%B7/cmake%E8%AE%BE%E7%BD%AE%E7%BC%96%E8%AF%91%E9%80%89%E9%A1%B9%E7%9A%84%E8%AE%B2%E7%A9%B6(add_compile_options%E5%92%8CCMAKE_CXX_FLAGS%E7%9A%84%E5%8C%BA%E5%88%AB%EF%BC%89/CF1B46CB-A4F3-4CF1-B53E-A47FF7986466.png)
/%E5%B7%A5%E5%85%B7/Homebrew%E7%9A%84%E4%B8%A4%E4%B8%AA%E4%BC%98%E7%82%B9/790FEEC9-494C-4441-864B-BE0175E17234.png)
/%E5%B7%A5%E5%85%B7/Homebrew%E7%9A%84%E4%B8%A4%E4%B8%AA%E4%BC%98%E7%82%B9/65828BEC-D05C-48BC-9972-897577AF78C1.png)
/%E5%B7%A5%E5%85%B7/cmakelist%E7%AE%A1%E7%90%86%E7%9A%84%E4%B8%80%E8%88%ACc++%E9%A1%B9%E7%9B%AE%E7%BB%93%E6%9E%84/1822C0F4-16CC-4CE5-9120-59EB25FF30AC.png)