2018年9月28日 下午11:16
如果用数学来解释的话:相当于是对常数进行求导,那么结果必然为0
- 首先需要说明的是,这一趟只有一个数据。
- 下图中的导数反映的是:w这条边对最后结果L有多少的影响力。
- 导数=0,说明对结果L的影响力为0。
- 导致w这条边的值w在处理下一个数据的时候是没有被变更的。
- 在这种情况下的坏处是:影响力为0,说明这个位置的点数据(神经元)是不重要的,但是一旦这个位置数据受到污染,那么他就会按初始化的权重值w来影响预测,并且影响还很大。
- 在下面这个例子中很能体现这一点。
%E4%B8%AD%E5%A6%82%E4%BD%95%E8%AE%AD%E7%BB%83%E4%B8%80%E6%9D%A1%E8%BE%B9%E7%9A%84%E6%9D%83%E9%87%8D%E7%9A%84/423718E2-90E1-4A35-A5A1-0094FC4E7862.png)
%E4%B8%AD%E5%A6%82%E4%BD%95%E8%AE%AD%E7%BB%83%E4%B8%80%E6%9D%A1%E8%BE%B9%E7%9A%84%E6%9D%83%E9%87%8D%E7%9A%84/AC848C2E-84F3-4A7C-BEB9-808C2063FE02.png)
2018年9月28日 下午11:16
如果用数学来解释的话:相当于是对常数进行求导,那么结果必然为0
2018年9月28日 下午10:01
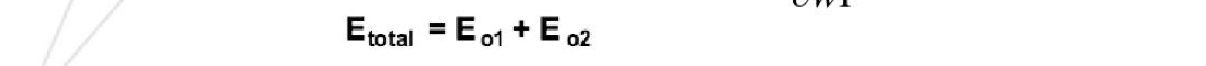
2018年9月28日 下午10:22
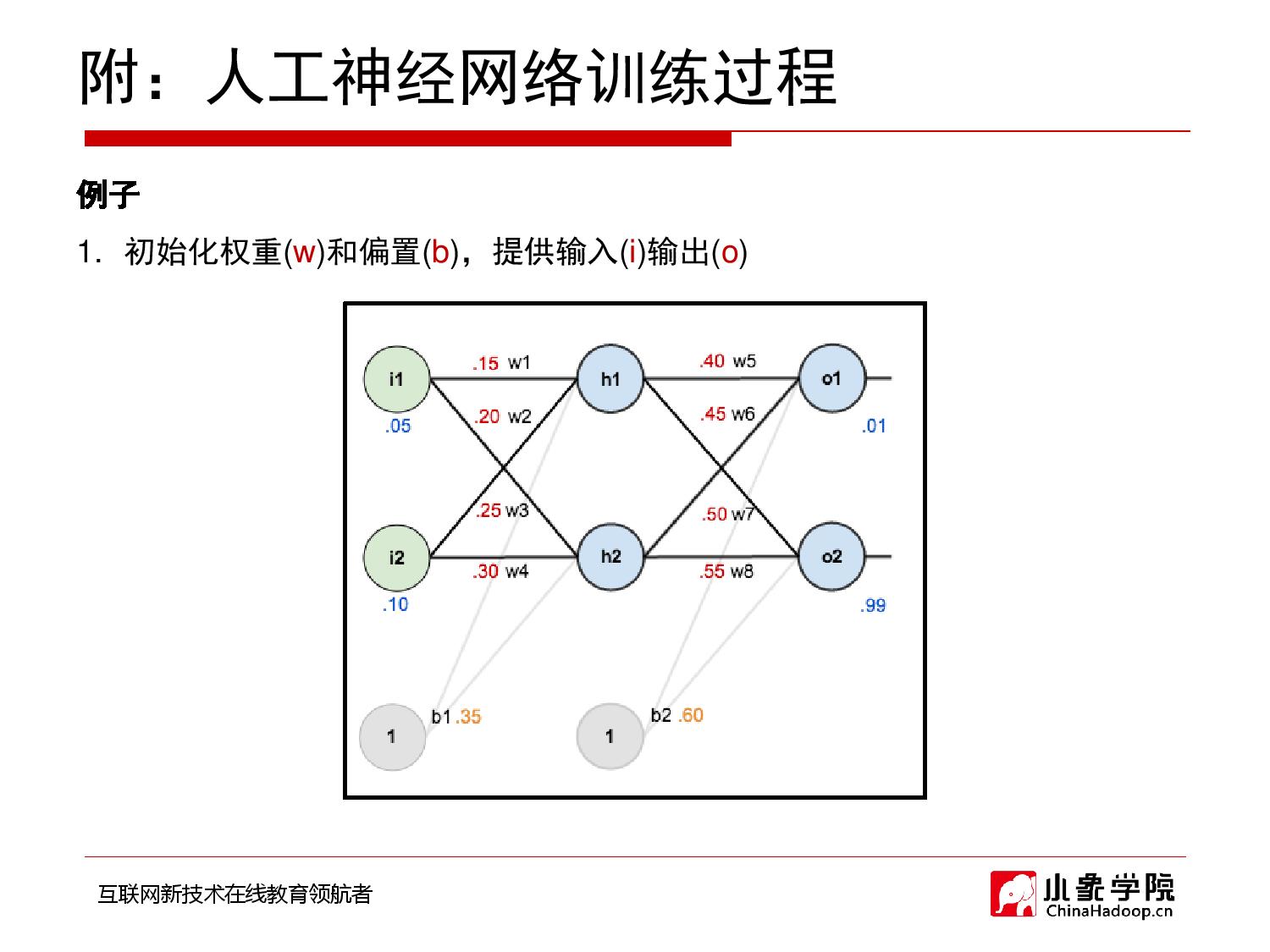
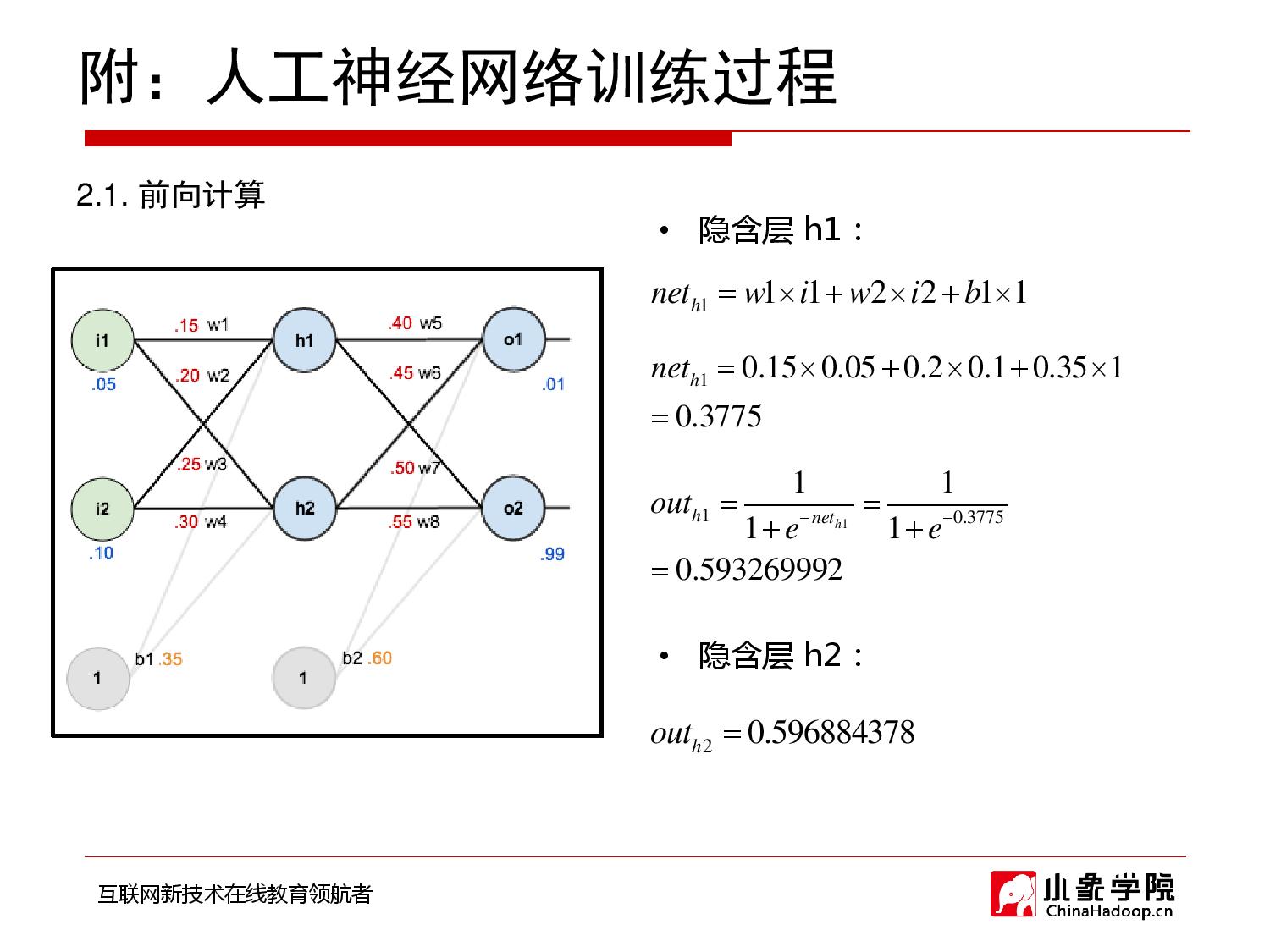
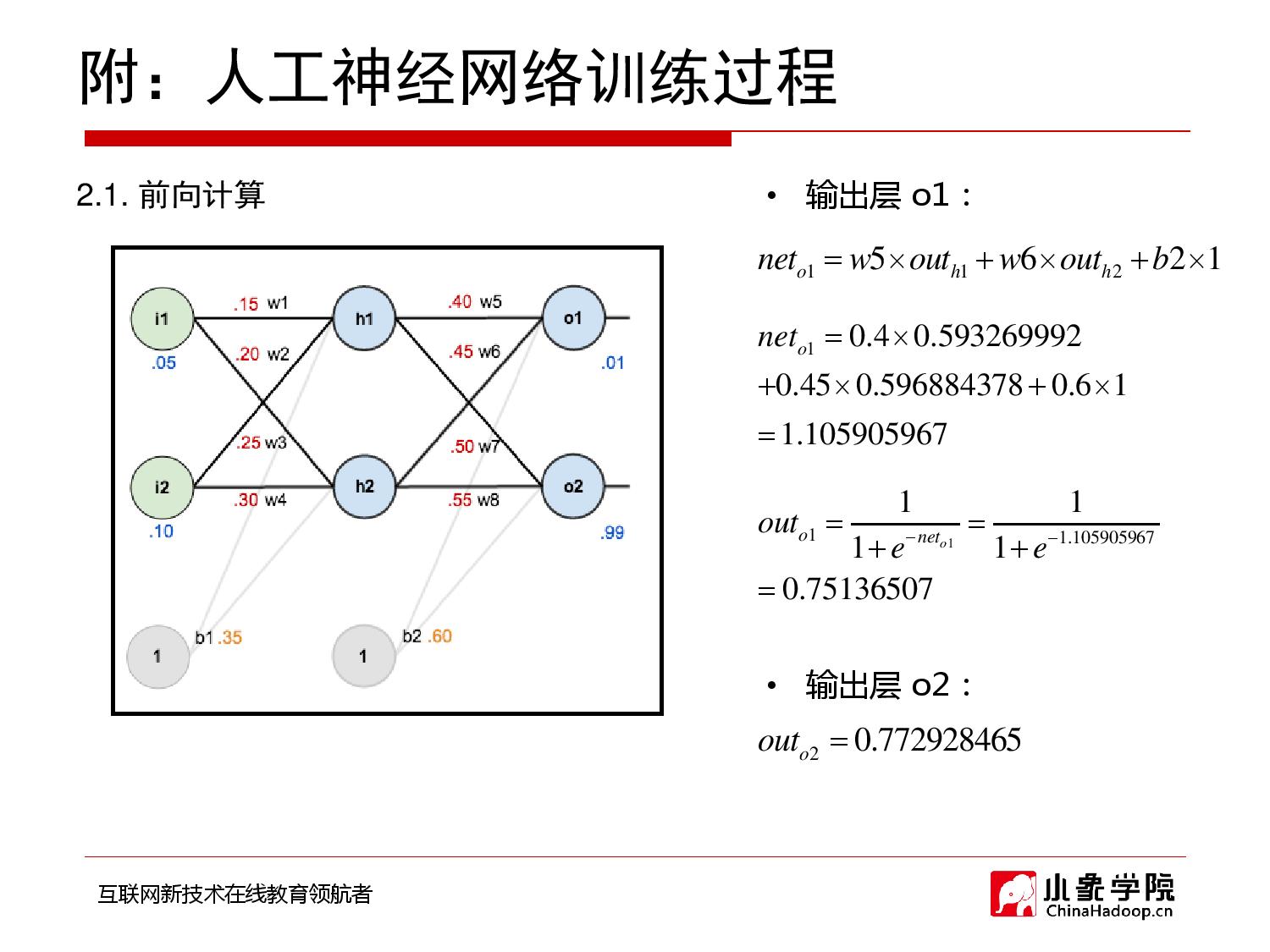
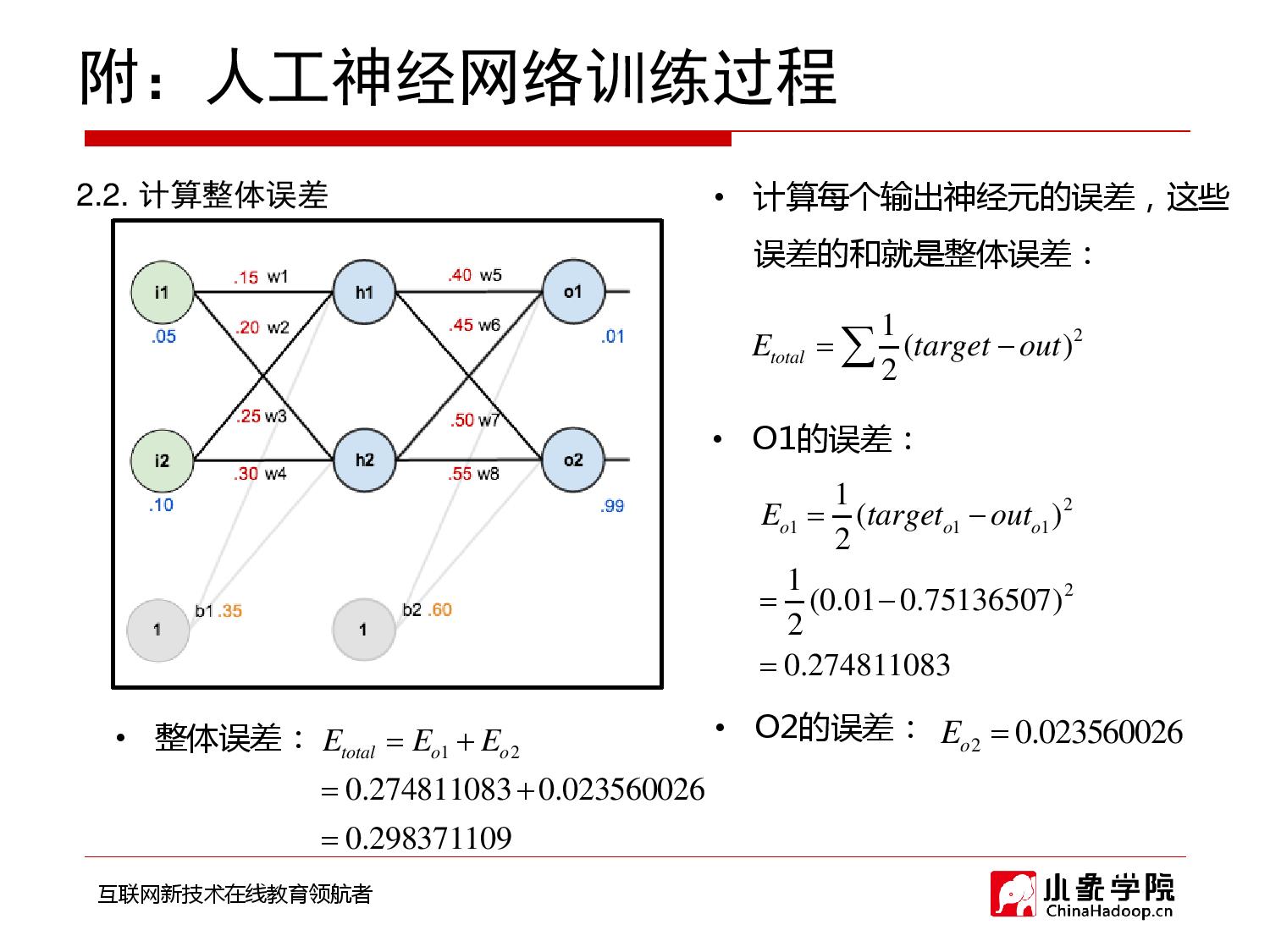
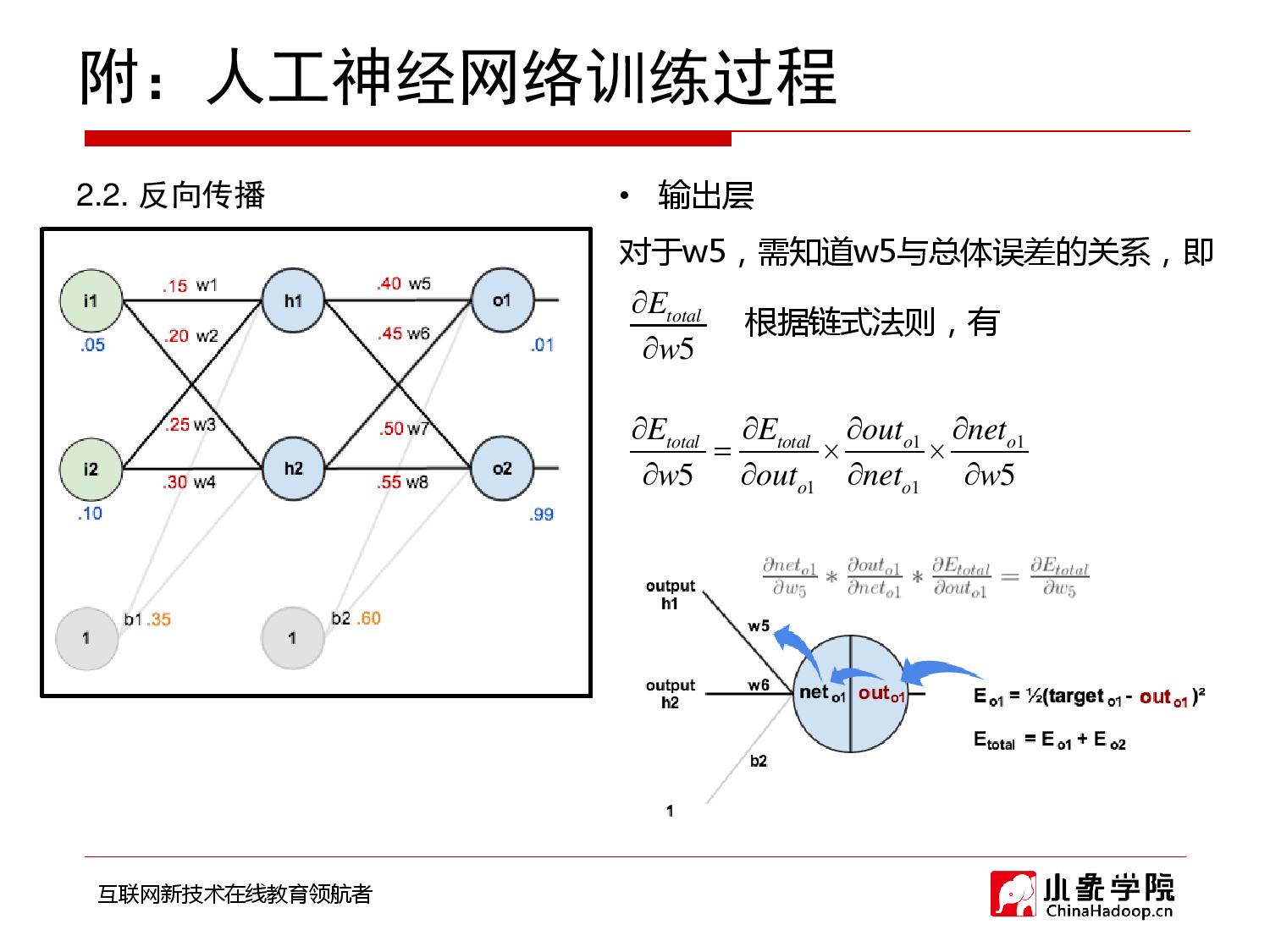
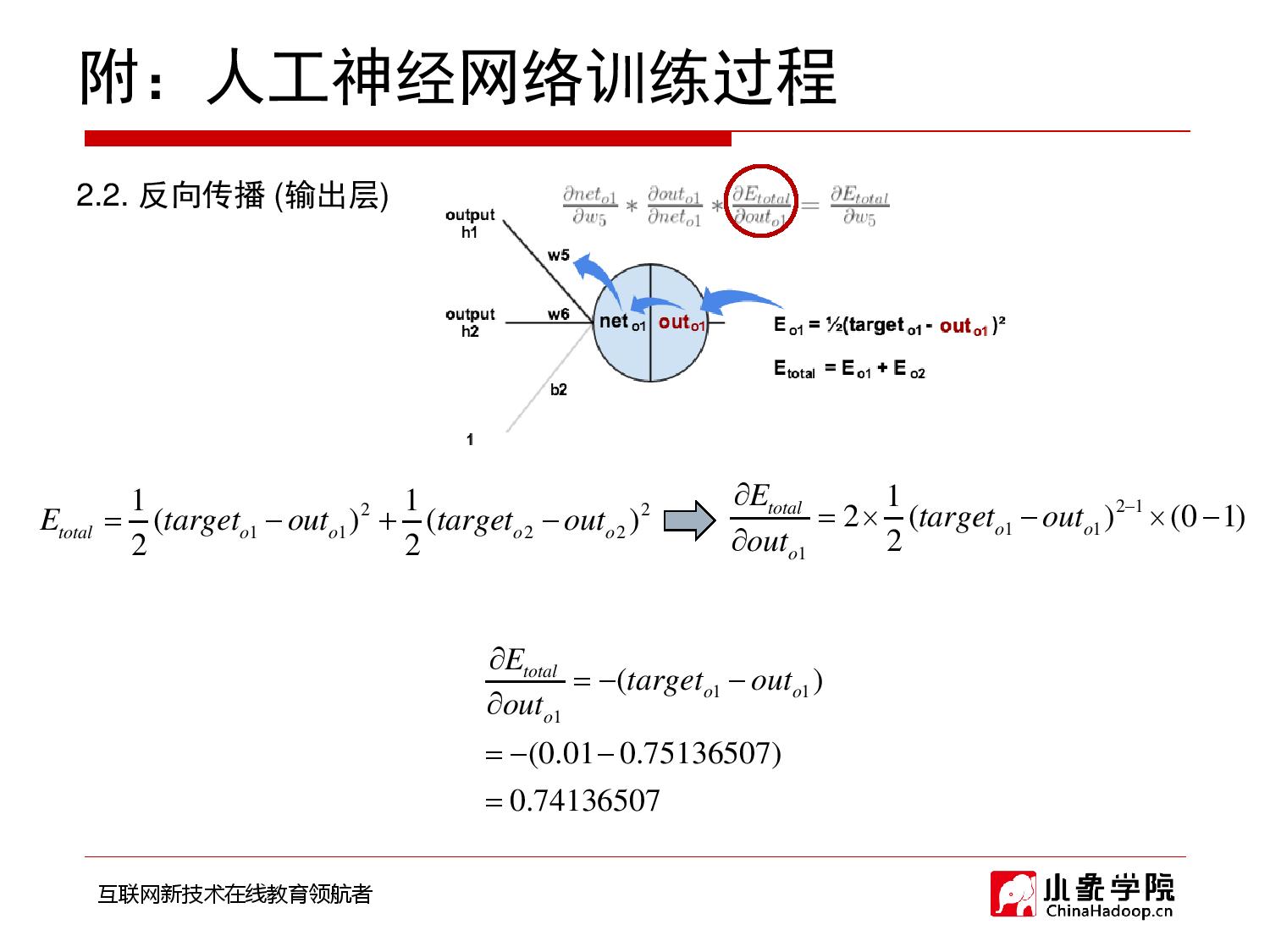
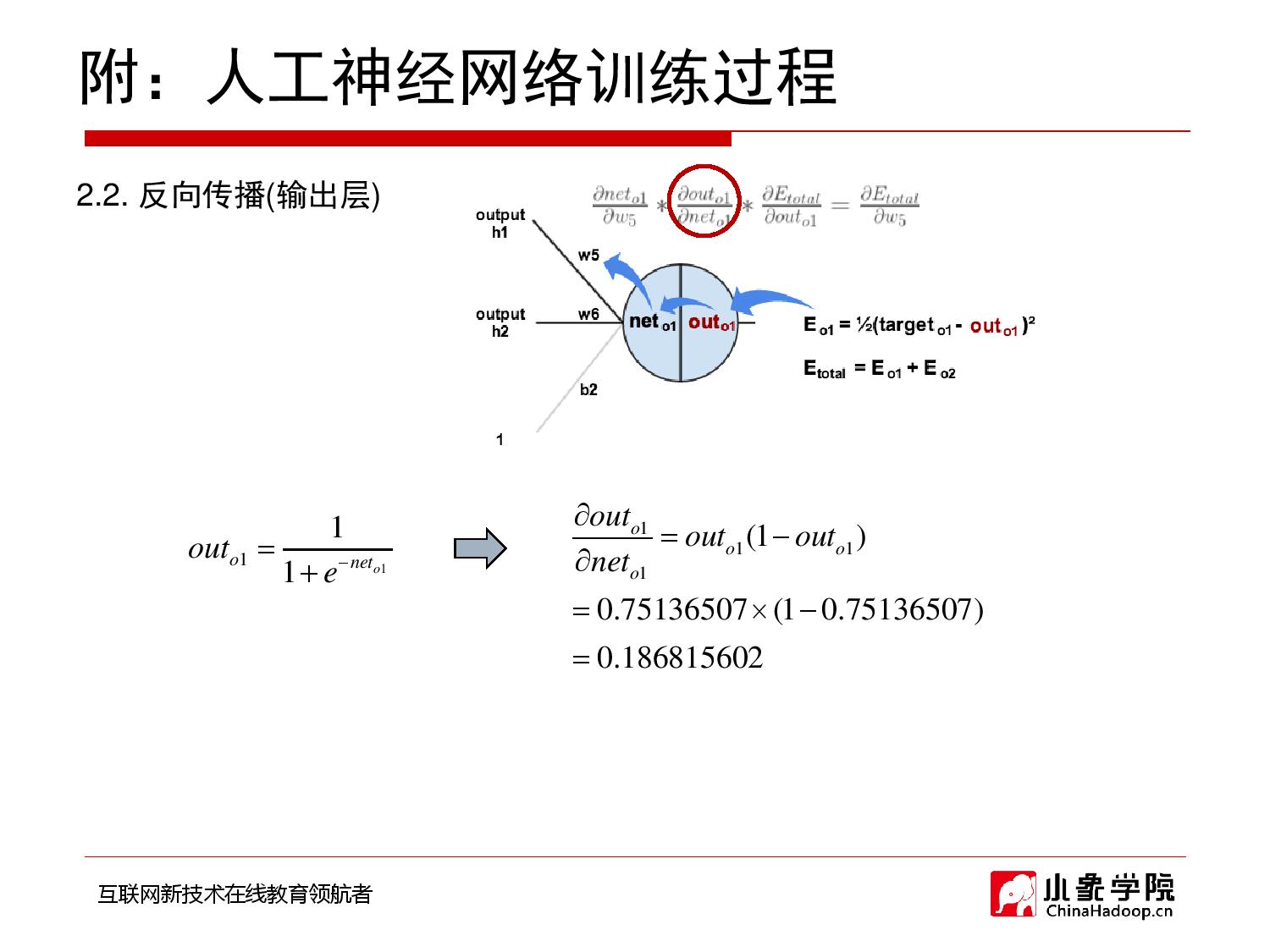
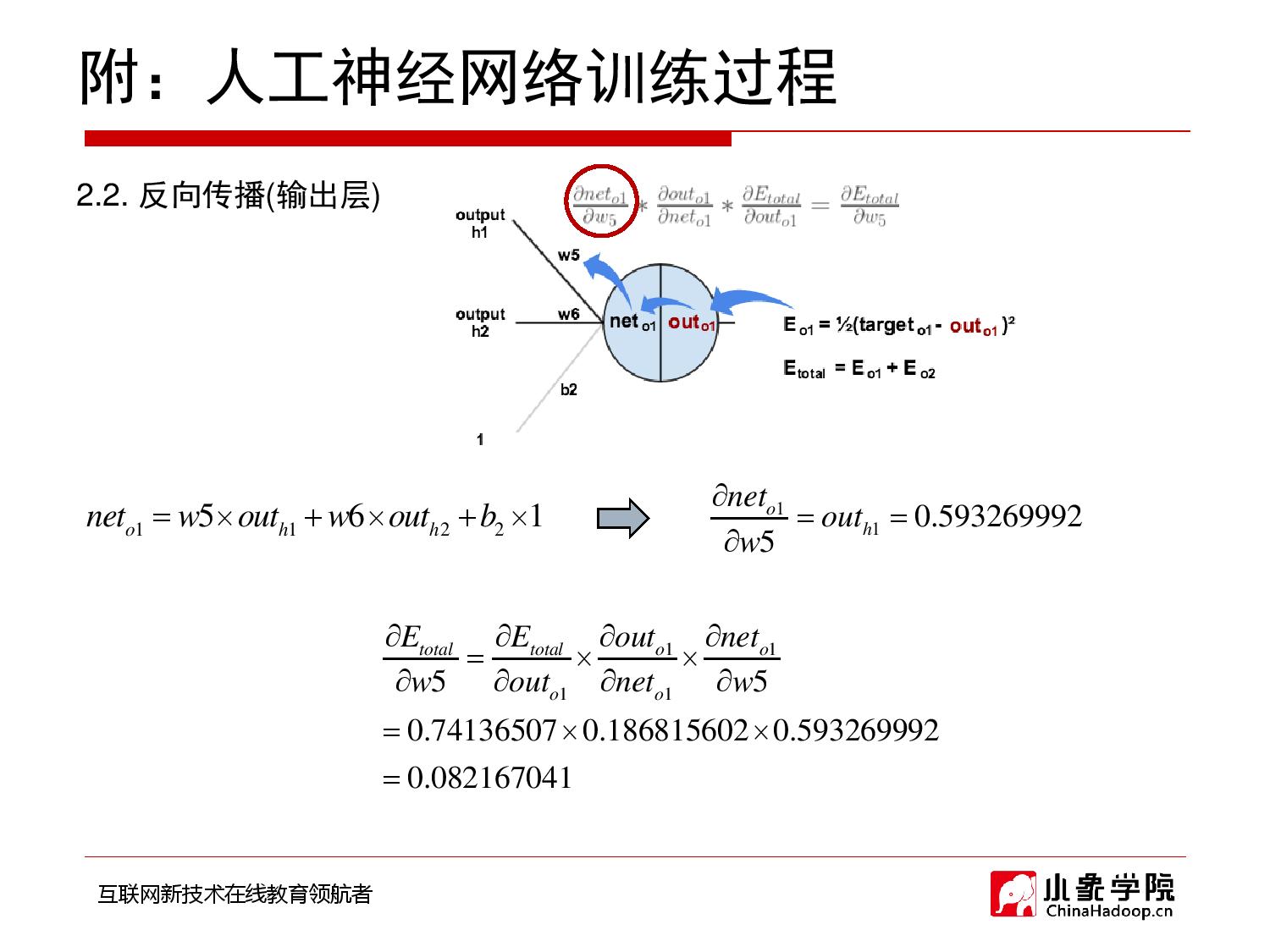
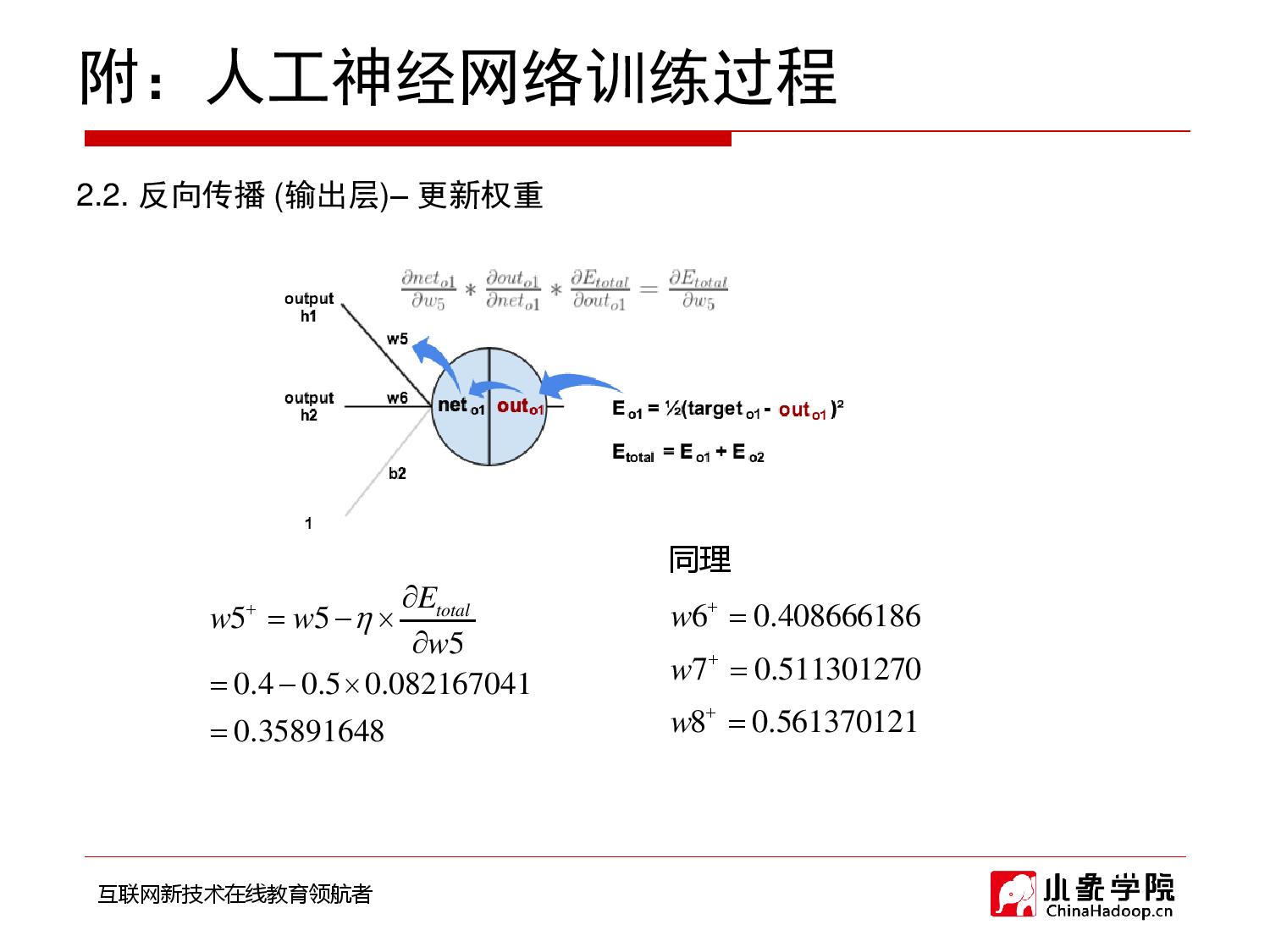
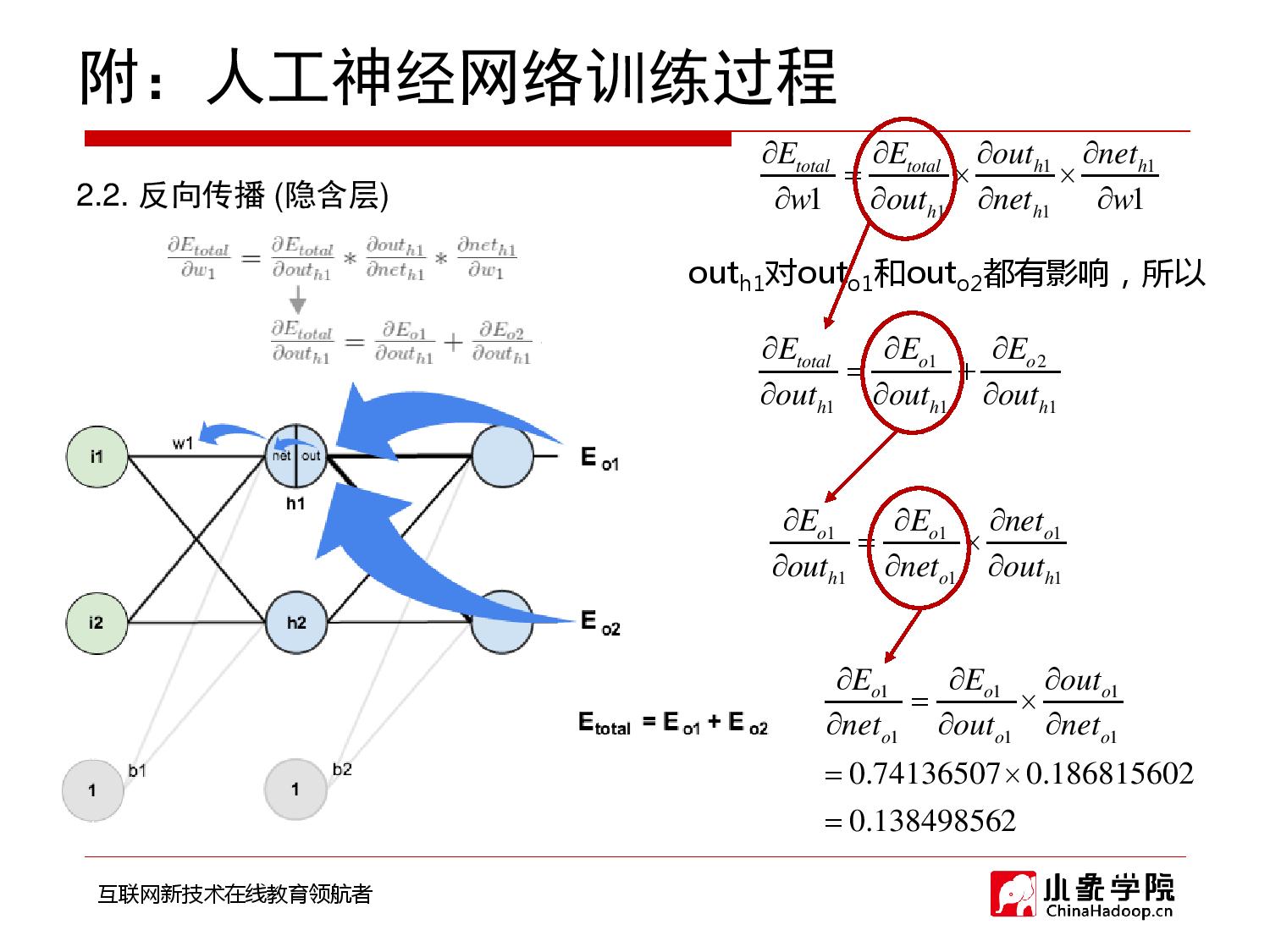
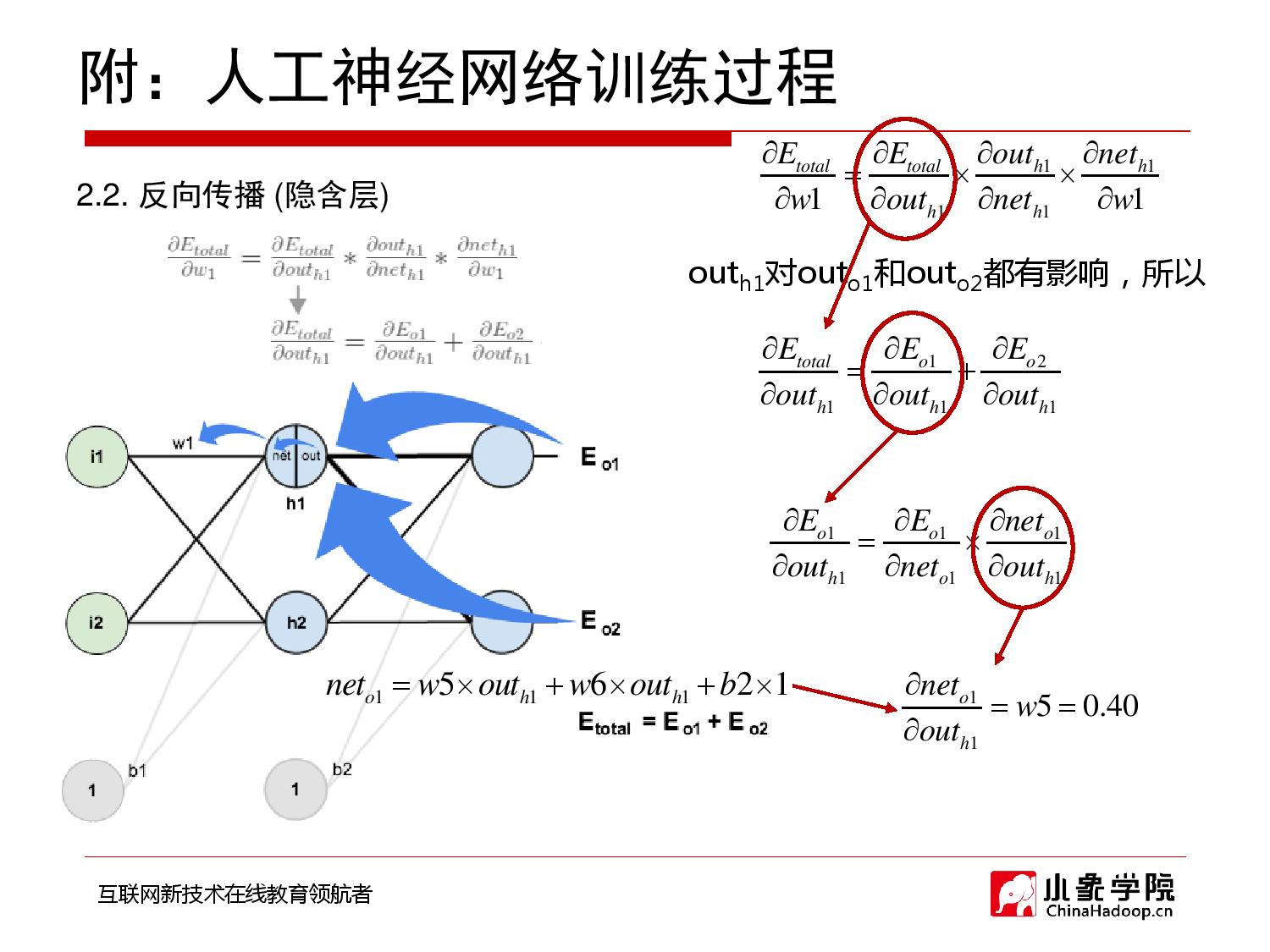
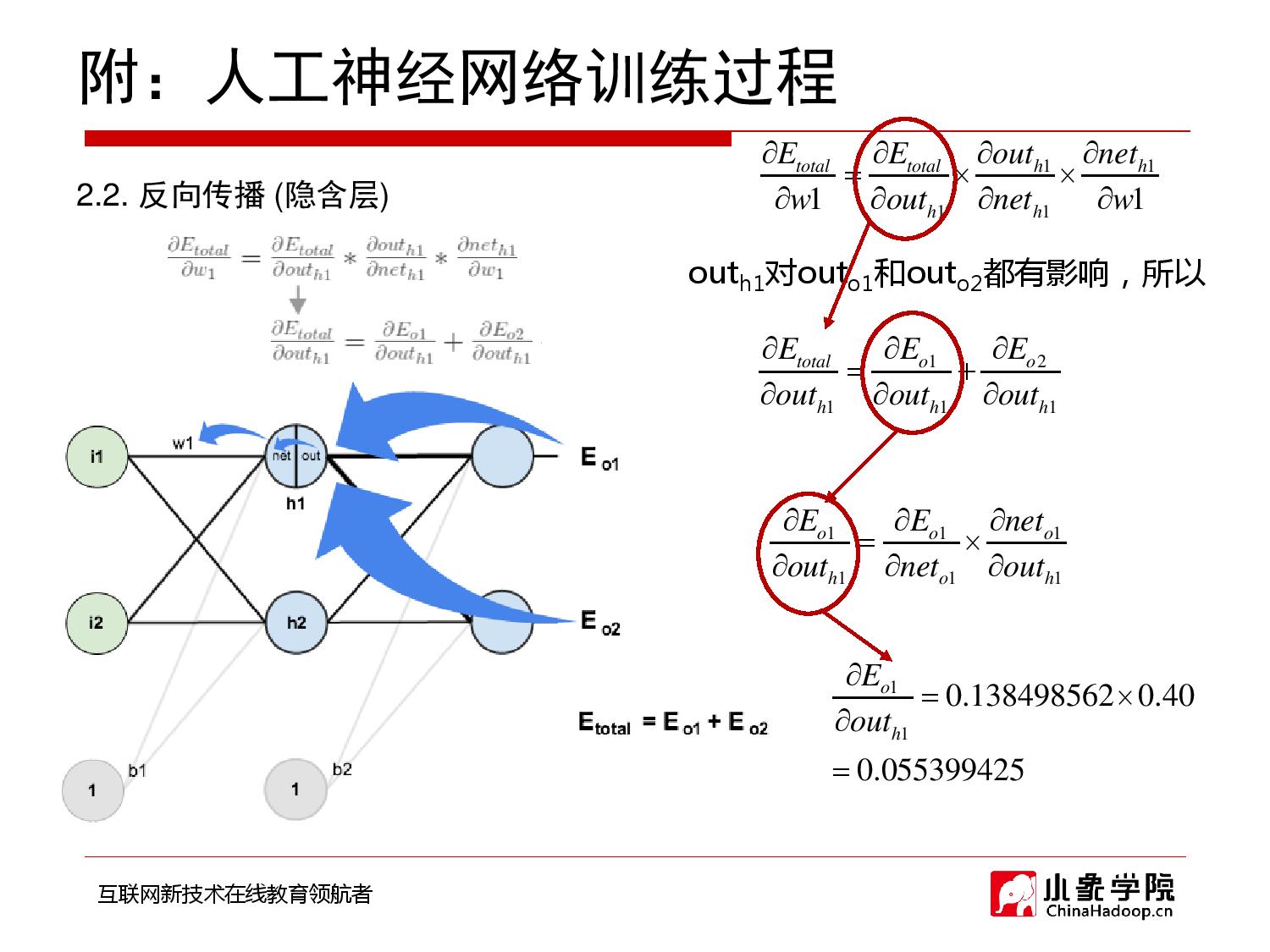
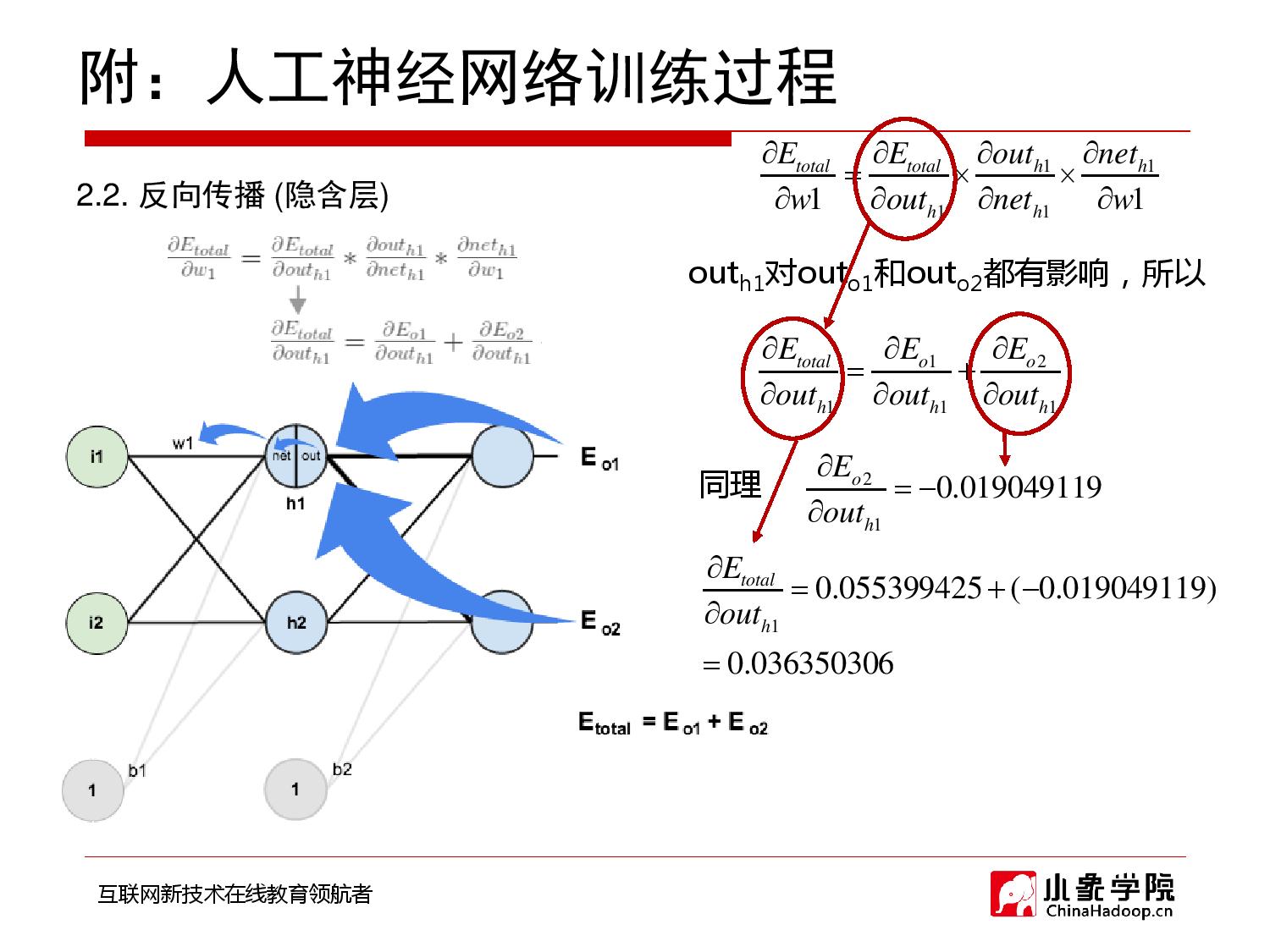
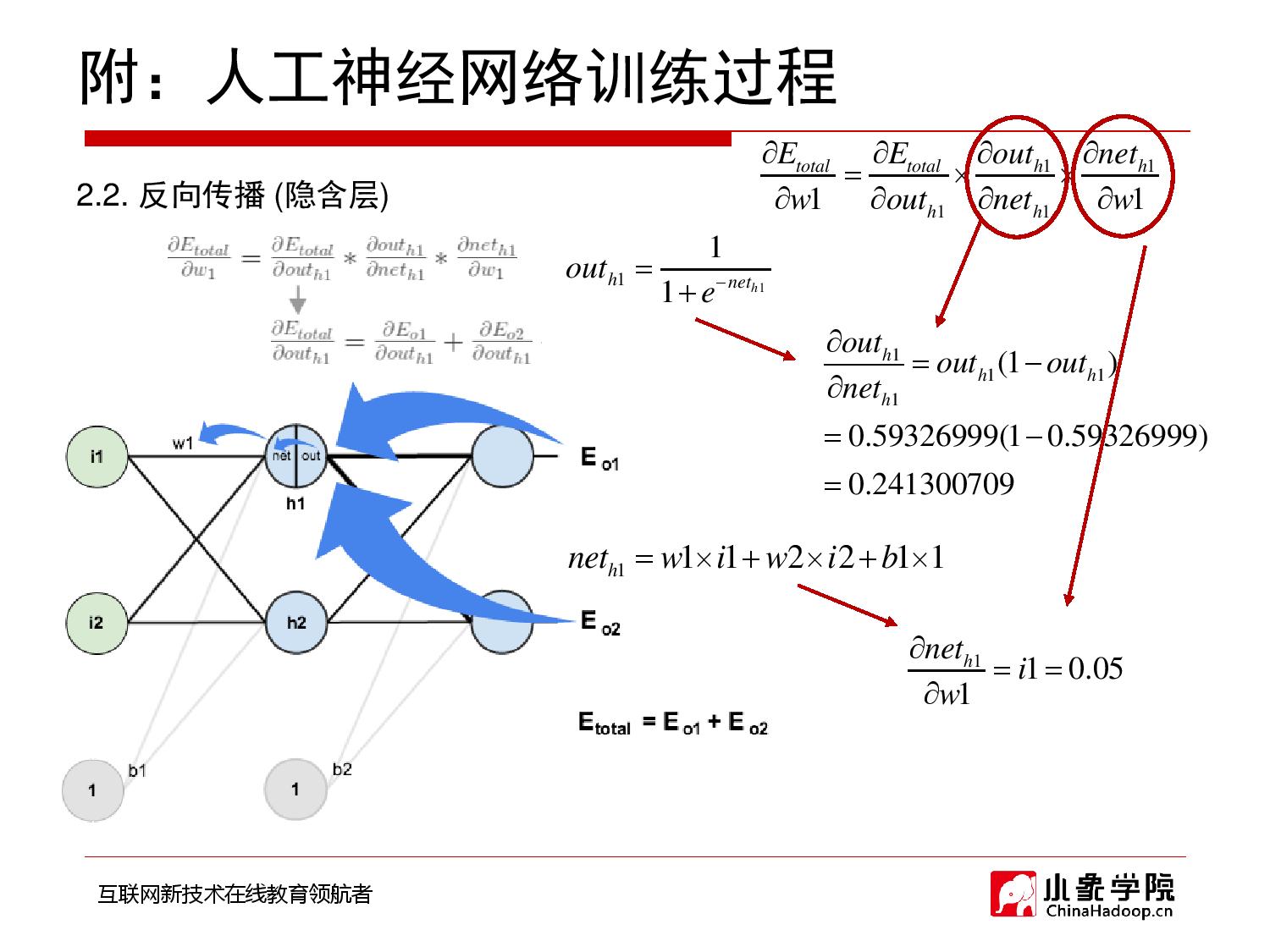
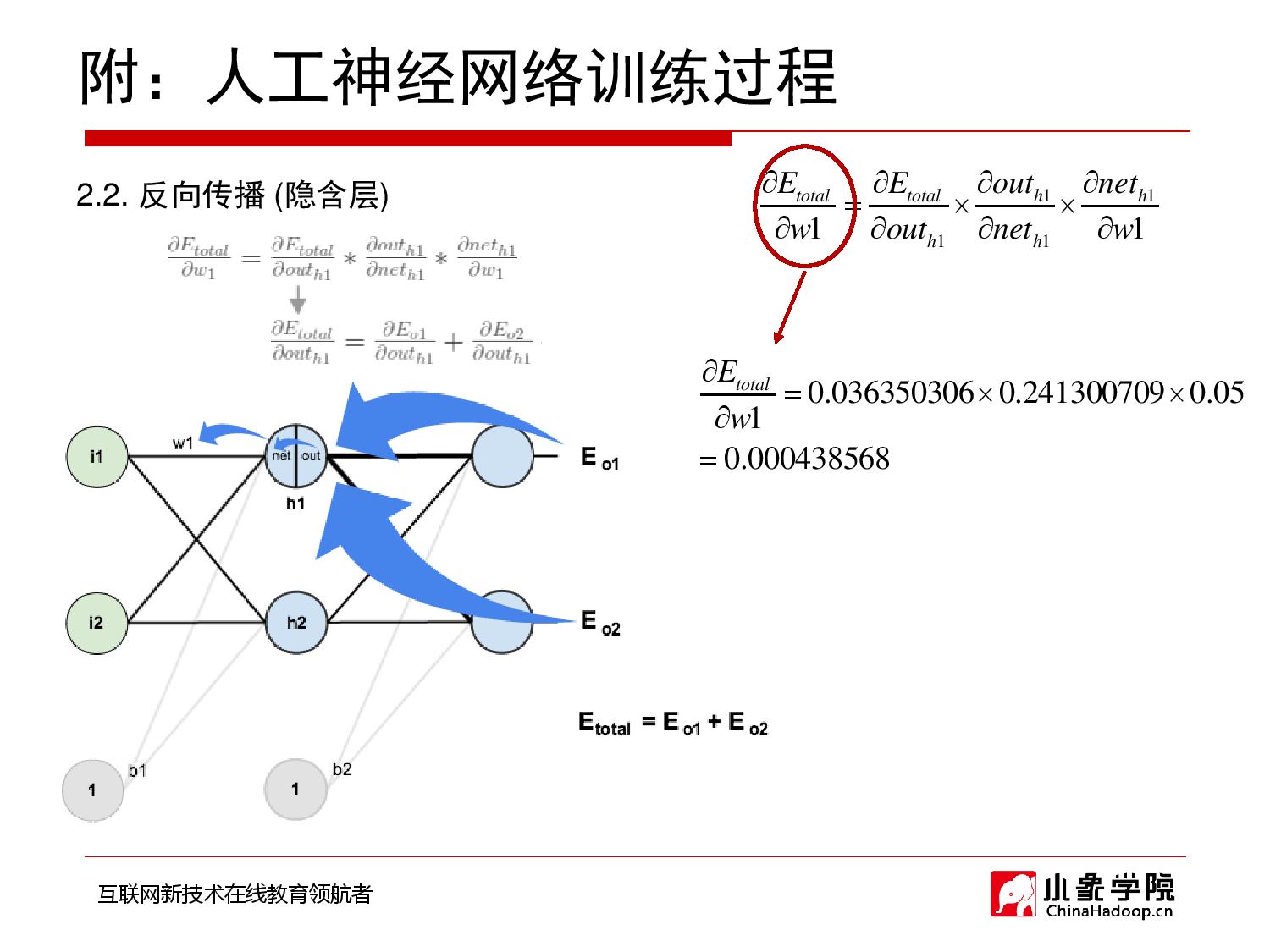
2018年9月28日 下午9:33
当我们分批学习时,每次使用过全部训练数据完成一次Forword运算以及一次BP运算,成为完成了一次epoch。
batch:是用多个局部最优,最后平均出一个全局最优。
全数据集:是直接求出全局最优。
结论:如果数据集较小,可以采用全数据集(Full batch learning)的形式
2018年9月28日 下午8:46
我现在理解其实频率图像其实就是数据的另外一种编码格式而已。
就比如说在sift也是一种对于图像特征的一种编码方式
理解:
2018年9月28日 下午1:51
2018年9月28日 下午1:47
文本数据预处理:sklearn 中 CountVectorizer、TfidfTransformer 和 TfidfVectorizer - CSDN博客
2018年9月26日 下午8:07
2018年9月18日 下午3:54
B树和B+树的插入、删除图文详解 - nullzx - 博客园
总结:
2018年9月18日 下午3:54
【数据结构和算法05】 红-黑树(看完包懂~) - CSDN博客
注:这个里面没有删除
The-Art-Of-Programming-By-July/03.01.md at master · julycoding/The-Art-Of-Programming-By-July · GitHub
这个有删除
http://www.cs.princeton.edu/~rs/talks/LLRB/RedBlack.pdf
2018年9月11日 下午8:14
关于使用 git 合作开发时的通用操作 - 个人文章 - SegmentFault 思否
多人开发的 Git 流程 - Android - 掘金

