2018年10月11日 上午10:23
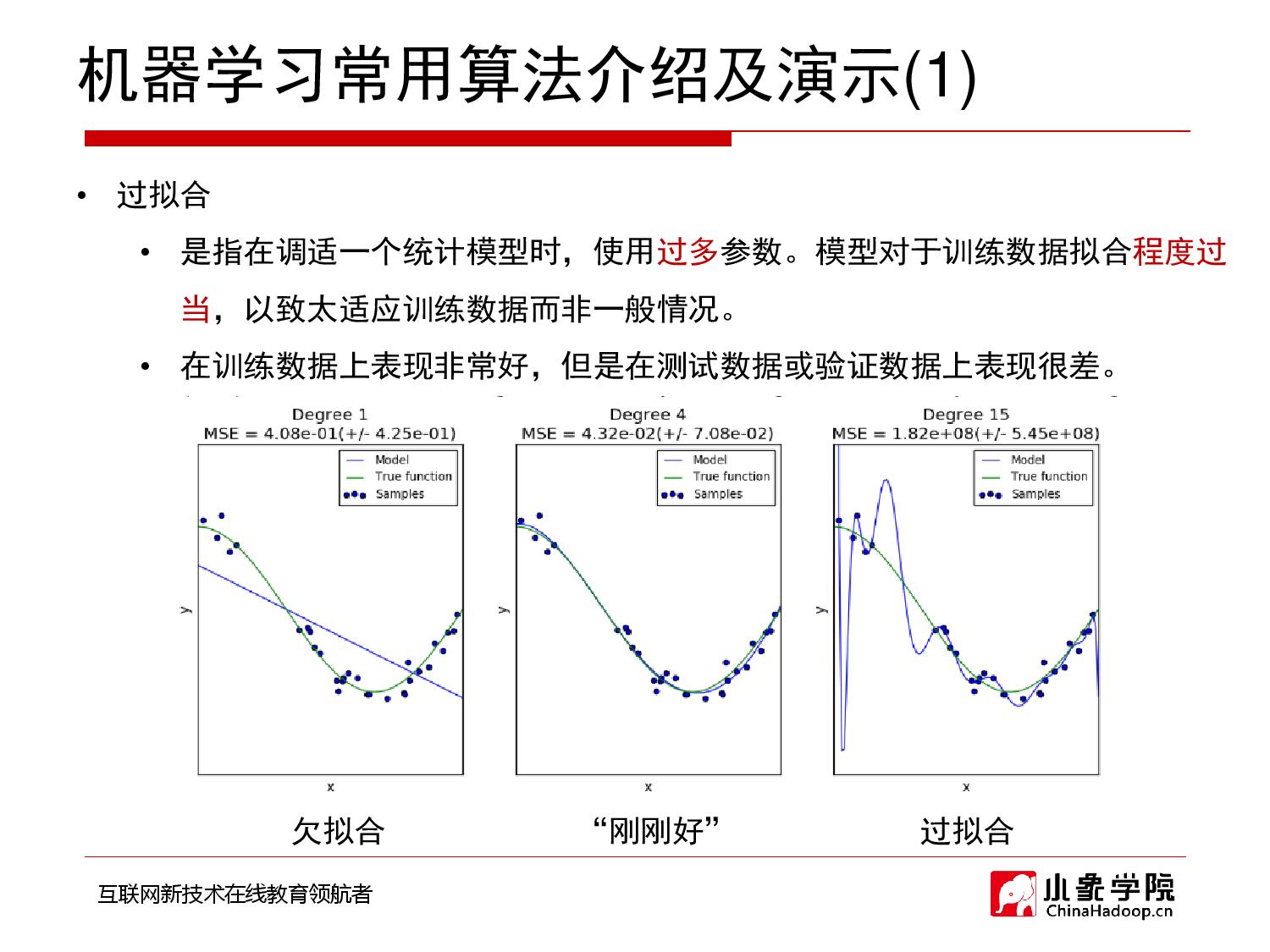
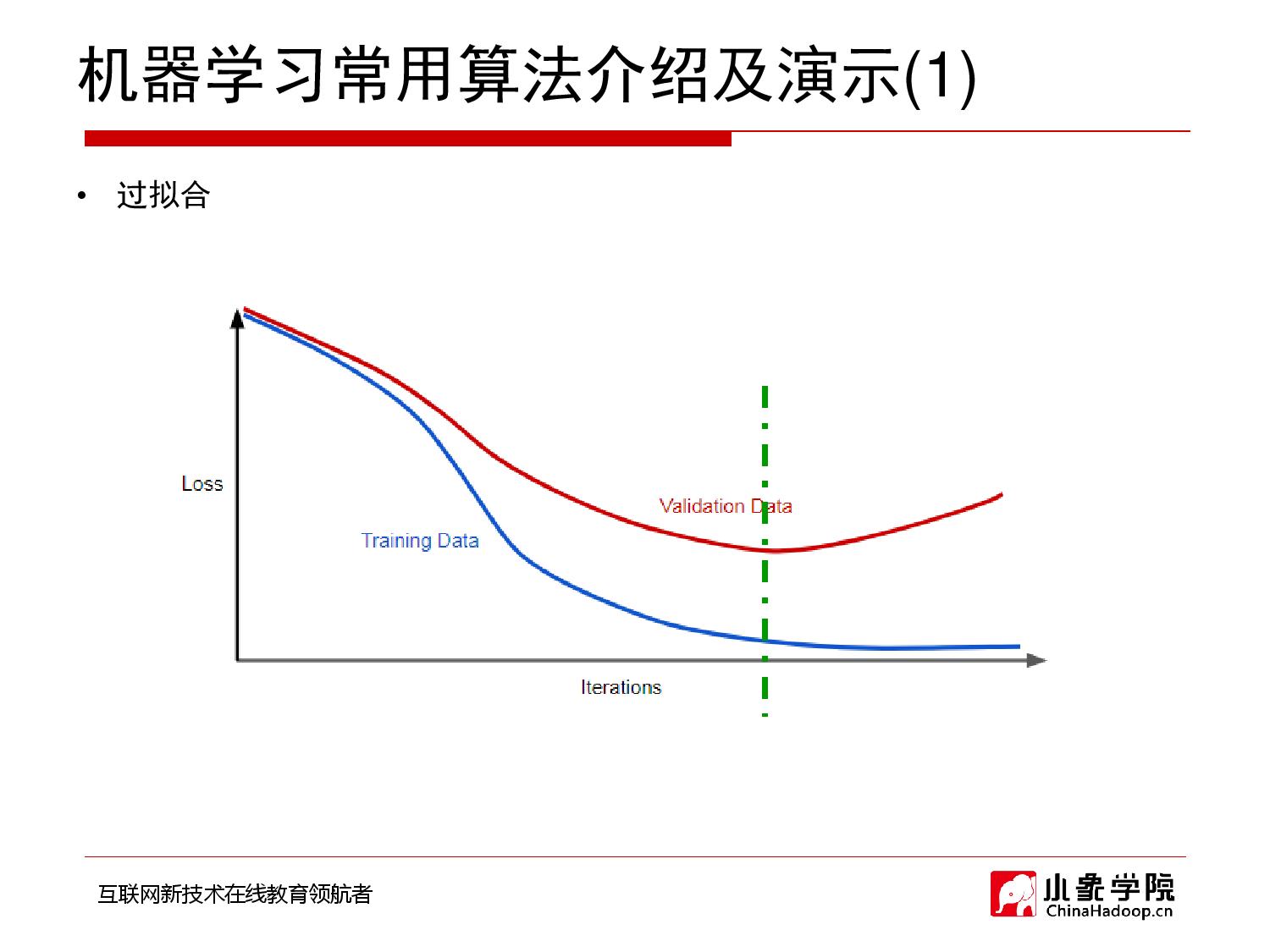
- 基本常识:模型复杂度高——>容易过拟合。
- 那么,我们为了防止过拟合,就min模型复杂度。
- 再联系到:我们也要求min:loss。
- 所以就联合起来表示为:min(loss+模型复杂度)
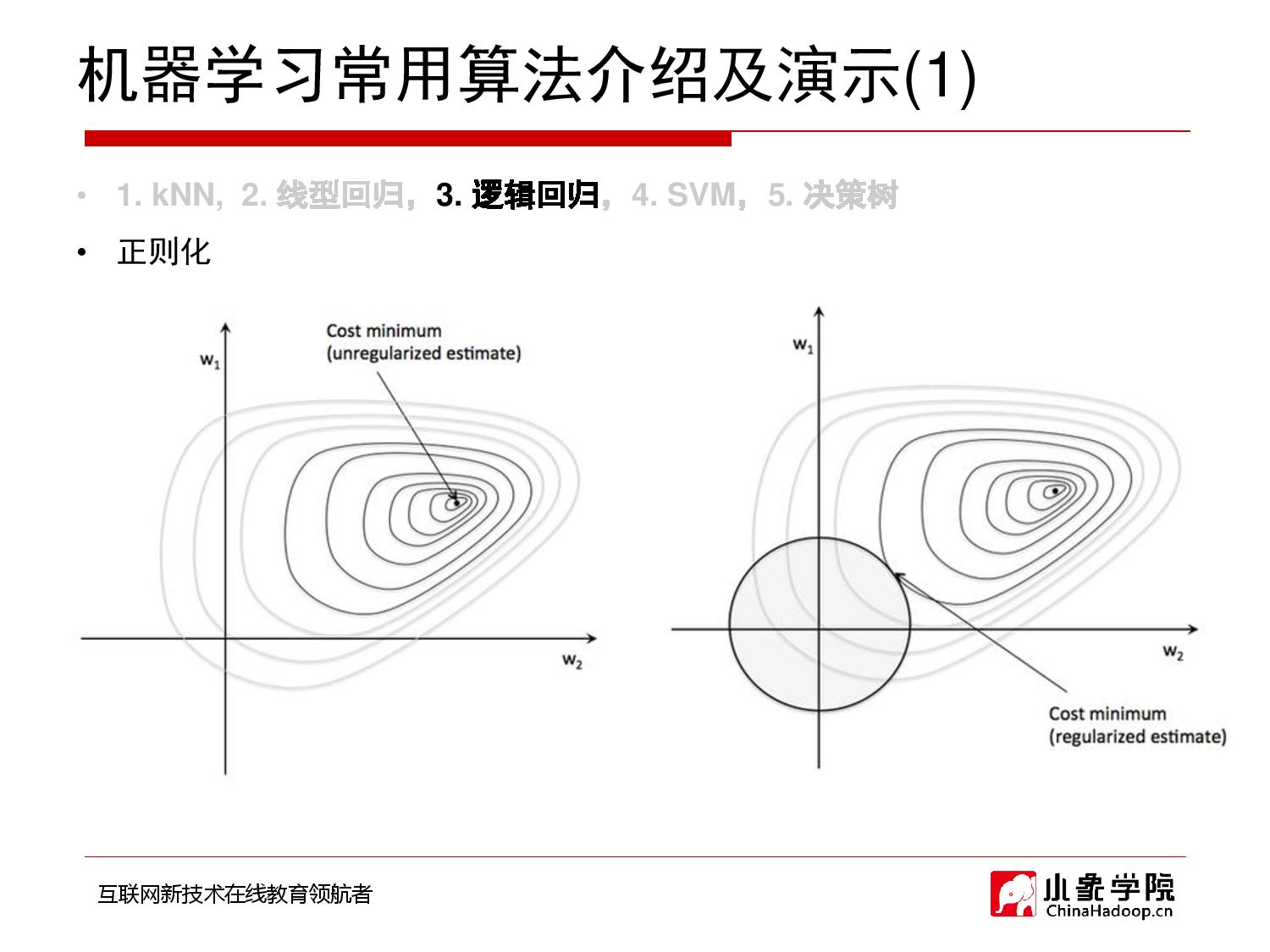
- 模型复杂度的定量(函数)描述:
- 第一种:L2正则化,我们通过模型的参数去模拟复杂度,也就是权重。
- 为啥通过模型参数去模拟?
- 为了尽可能的防止,有人因为单方面突出,而且正好这个方面对应的权重还大。这个人不就其他因素不用考虑了,就直接晋级了吗
- 当然,如果我们的模型目的就是为了添加突出单方面强的选手,那么,我们甚至可以不加正则化项
- 并且,参数权重大并不直接等价于,最后分数大。一个大的权重,但是乘以一个很小的数,最后结果也不一定大
- 最重要的一个问题是?
- 我们当前这个模型的容错度,你希望是怎样的?
- 这就决定了你的模型复杂度的权重。
- 模型复杂度的定量描述还有那些?




- 我们当前这个模型的容错度,你希望是怎样的?