2018年10月13日 下午6:48
主要:
详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解 - nebulaf91的博客 - CSDN博客
次要:
基础:常见的参数估计方法 - 简书
- ::概率和统计是一个东西吗?::
- 一句话总结:概率是已知模型和参数,推数据。统计是已知数据,推模型和参数。
- MLE和MAP都是统计领域的问题。它们都是用来推测参数的方法
- ::贝叶斯公式到底在说什么?::
- 贝叶斯公式就是在描述,你有多大把握能相信一件证据?(how much you can trust the evidence)
- 从这个角度总结贝叶斯公式:做判断的时候,要考虑所有的因素。
- 从这个角度思考贝叶斯公式:一个本来就难以发生的事情,就算出现某个证据和他强烈相关,也要谨慎。证据很可能来自别的虽然不是很相关,但发生概率较高的事情
- ::似然函数和概率函数的区别?::
- 对于这个函数:
- P(x|θ)
- 输入有两个:x表示某一个具体的数据;θ表示模型的参数。
- 如果θ是已知确定的,x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点x,其出现概率是多少。
- 如果x是已知确定的,θ是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。
- 对于这个函数:
- ::最大似然估计(MLE)::
- 具体问题:
- 假设有一个造币厂生产某种硬币,现在我们拿到了一枚这种硬币,想试试这硬币是不是均匀的。即想知道抛这枚硬币,正反面出现的概率(记为θ)各是多少?
- 抽象问题:
- 在二项分布中,事件发生的概率p是多少。这里的p就等价于θ,是问在似然函数中,θ是多少?
- 思路:
- 这是一个统计问题,回想一下,解决统计问题需要什么? 数据!
- 当这个二项函数,数据填入之后就变成了一个,未知量为θ的函数
- 最大似然法认为:当前出现的样本正好对应着总体中概率最大的那个事件;
- 因为,总体中概率最大的事件实际出现(即被抽样选中)的概率是最大的。
- 这时这个函数就有了一个等式,就可以求出未知量为θ了
- 总结:因此,最大似然参数求解的核心思想就是构造当前样本出现的联合概率函数,对其求偏导,让当前样本的概率最大的就是模型参数。
- 具体问题:
- ::最大后验概率估计MAP::
- 求解推导1:
- 最大似然估计是求参数θ, 使似然函数P(x0|θ)最大。
- 最大后验概率估计则是想求θ使P(x0|θ)P(θ)最大。
- 求得的θ不单单让似然函数大,θ自己出现的先验概率也得大。 (这有点像正则化里加惩罚项的思想,不过正则化里是利用加法,而MAP里是利用乘法)
- MAP其实是在最大化P(θ|x0)=P(x0|θ)P(θ)/P(x0)
- 求解推导2:
- 正如最大似然估计中假定x1,x2,x3,..每次独立抽样的概率模型相同,也就是θ不变,现在我们去掉这个假设,将问题复杂化。
- 假如x1,x2,x3,..每次独立抽样的概率模型中的参数θ不是一个固定值,而是一个符合g(θ)概率分布(先验概率)的随机变量。这时,我们就需要用到最大后验估计。
- 为啥使用了先验分布,可以将结果拉向更加正确的位置?
- MLE求出来是估计的,而g(θ)是咱们自己的生活经验。其实有时候生活经验也很重要,但是却没有理论的支撑。这次就像是要把理论和经验结合起来。
- 举个例子:
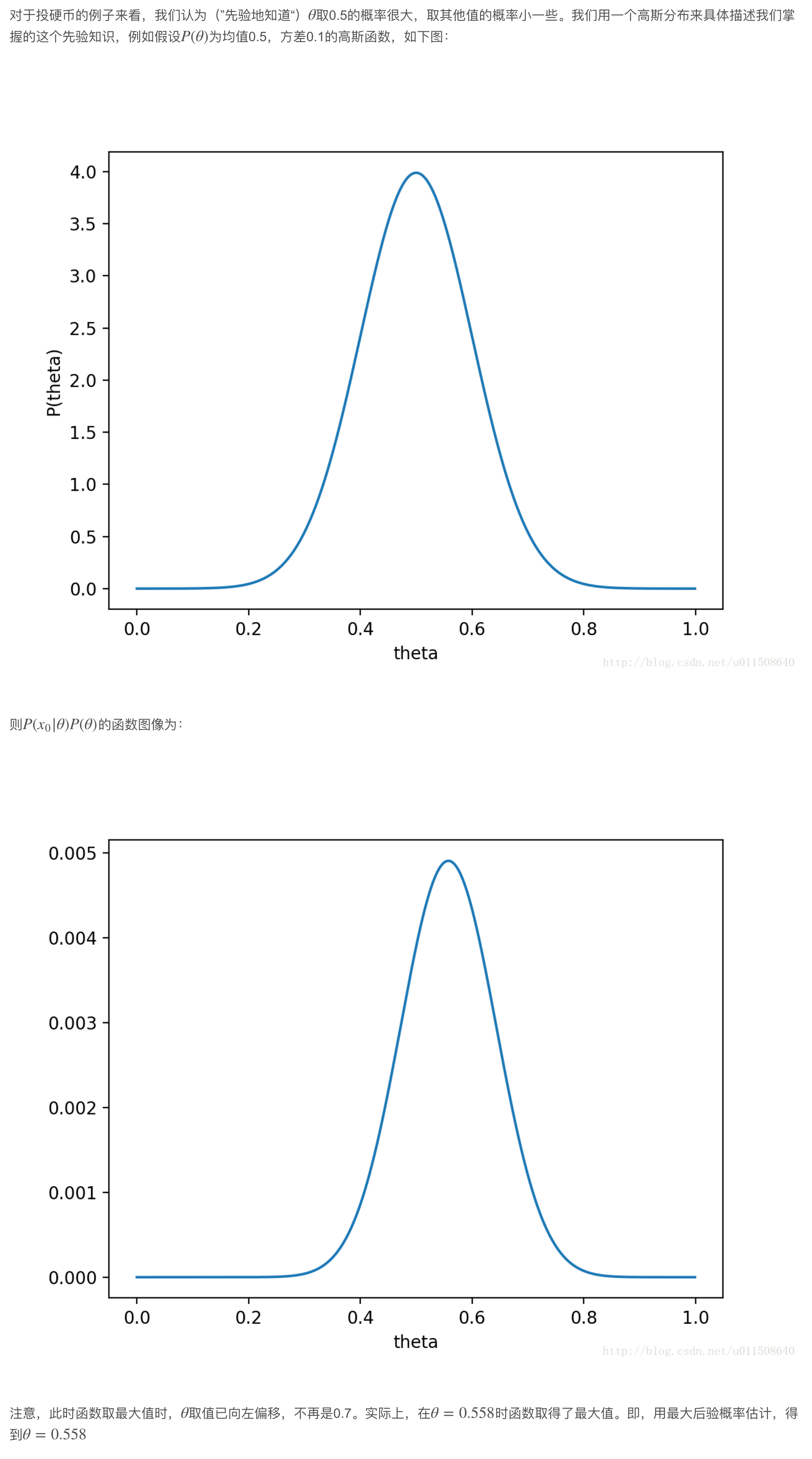
- 求解推导1: