2019年3月15日 下午1:24
2019年3月16日 下午3:36
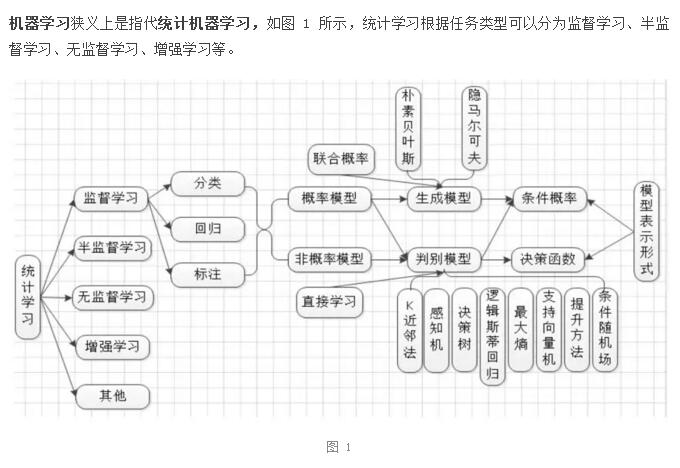
生成模型和判别模型不可以通用吗?
- 我们已知:模型是对“关系”的描述方式
- 生成模型和判别模型他们描述的关系是?
- 生成模型:(x,y)同时出现的可能性
- 判别模型:x与y关系强弱的大小
- 我们已知:模型很傻,我们给他啥他就能学到啥
- 共同点:
- 样本相同:两个模型的输入数据可以是相同的,也就是样本是相同的。
- 目的大致相同:我们要用已知样本去估计出一个描述某种关系的模型。
- 由于我们具体目的的不同,一个是求P(x,y)一个是P(y|x),我们就要选择分别选择合适的模型,因为不同的模型本身就有各自擅长,也由于目的的不同,我们选择的运用的知识也不同。
2019年3月15日 下午1:24
机器学习“判定模型”和“生成模型”有什么区别? - 知乎
生成模型 VS 判别模型 (含义、区别、对应经典算法) - Taylover-Cam的博客 - CSDN博客
任正非:机器学习就是概率统计
其实机器学习的任务是从属性X预测标记Y,即求概率P(Y|X);
从建模的角度来区分
判别模型是对条件概率p(Y|X)建模,生成模型是对联合概率P(X,Y)建模。
机器学习 - 判定模型与生成模型的区别 - SegmentFault 思否
最基本的区别就是建模对象不同, 但目的都是求出P(Y|X)
- 判别模型Discriminative Model:
- 直接对P(Y|X)进行建模, 判别模型不考虑如何生成 X 和 Y 的联合事件, 比如 SVM 只考虑把点分开而已, 鲁棒性比较强, 但需要更多的训练数据.
- 生成模型 Generative Model:
- 利用贝叶斯公式, 先对P(X|Y)进行建模, 然后利用训练集中的 P(Y) 求出联合概率分布 P(X,Y), 最后除以X的概率分布P(X)得出我们的目标(P(Y|X)). 最常见的例子朴素贝叶斯. 生成模型需要做出更多的假设, 因此适用于数据较少的情况下, 但鲁棒性不强, 因为假设错了就效果很差了.
- 给一个鲁棒性不强的栗子,
- 外星人来地球拿了一个数据集包含了地球人的身体特征, 标签有2类:男和女. 如果训练数据集只有1%是数据是男性, 而99%是女性. 那么外星人科学家就有可能认为给定随机一个人类, 该人类是女性的P(y=female)概率是99%, 按照这个假设去做生成模型就会很不给力, 但判别模型就没有这个问题.

概念的理解:
- 在机器学习中任务是 从属性X预测标记Y
- 判别模型求的是P(Y|X),即后验概率;
- 而生成模型最后求的是P(X,Y),即联合概率。
- 从本质上来说:
- 判别模型之所以称为“判别”模型,是因为其根据X“判别”Y;
- 而生成模型之所以称为“生成”模型,是因为其预测的根据是联合概率P(X,Y),而联合概率可以理解为: “生成”(X,Y)样本 的概率分布(或称为 依据);
- 具体来说,机器学习已知X,从Y的候选集合中选出一个来,可能的样本有(X,Y_1), (X,Y_2), (X,Y_3),……,(X,Y_n),
- 实际数据是如何“生成”依赖于P(X,Y),那么最后的预测结果选哪一个Y呢?那就选“生成”概率最大的那个吧~
具体的例子:
假设你现在有一个分类问题,x是特征,y是类标记。用生成模型学习一个联合概率分布P(x,y),而用判别模型学习一个条件概率分布P(y|x)。
用一个简单的例子来说明这个这个问题。假设x就是两个(1或2),y有两类(0或1),有如下如下样本(1,0)、(1,0)、(1,1)、(2,1)
则学习到的联合概率分布(生成模型)如下:
————-—0———1—
——1— 1/2— -1/4
——2—— 0 ——1/4
而学习到的条件概率分布(判别模型)如下:
————-—0———1—
——1—— 2/3— 1/3
–—2—— 0 —-— 1
在实际分类问题中,判别模型可以直接用来判断特征的类别情况,而生成模型,需要加上贝叶斯法则,然后应用到分类中。但是,生成模型的概率分布可以还有其他应用,就是说生成模型更一般更普适。不过判别模型更直接,更简单。
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E5%9D%90%E6%A0%87%E7%B3%BB%E3%80%8C%E5%86%85%E5%A4%96%E5%8F%82%E3%80%8D%E7%9A%84%E8%AF%A6%E7%BB%86%E8%BD%AC%E6%8D%A2%E6%8E%A8%E5%AF%BC/7CF3A90E-502D-4581-B8BE-8552D200EC95.png)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E5%9D%90%E6%A0%87%E7%B3%BB%E3%80%8C%E5%86%85%E5%A4%96%E5%8F%82%E3%80%8D%E7%9A%84%E8%AF%A6%E7%BB%86%E8%BD%AC%E6%8D%A2%E6%8E%A8%E5%AF%BC/211EA450-533A-4F92-9B82-53A62D384A3B.png)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E5%9D%90%E6%A0%87%E7%B3%BB%E3%80%8C%E5%86%85%E5%A4%96%E5%8F%82%E3%80%8D%E7%9A%84%E8%AF%A6%E7%BB%86%E8%BD%AC%E6%8D%A2%E6%8E%A8%E5%AF%BC/%E6%9C%AA%E7%9F%A5.png)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E5%9D%90%E6%A0%87%E7%B3%BB%E3%80%8C%E5%86%85%E5%A4%96%E5%8F%82%E3%80%8D%E7%9A%84%E8%AF%A6%E7%BB%86%E8%BD%AC%E6%8D%A2%E6%8E%A8%E5%AF%BC/20160126193223989.jpg)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E5%9D%90%E6%A0%87%E7%B3%BB%E3%80%8C%E5%86%85%E5%A4%96%E5%8F%82%E3%80%8D%E7%9A%84%E8%AF%A6%E7%BB%86%E8%BD%AC%E6%8D%A2%E6%8E%A8%E5%AF%BC/20160126193236692.jpg)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E5%9D%90%E6%A0%87%E7%B3%BB%E3%80%8C%E5%86%85%E5%A4%96%E5%8F%82%E3%80%8D%E7%9A%84%E8%AF%A6%E7%BB%86%E8%BD%AC%E6%8D%A2%E6%8E%A8%E5%AF%BC/3E379E03-785E-4B82-9076-0667B2C2101D.png)



/%E7%9F%A5%E8%AF%86%E7%82%B9/%E4%BB%BF%E5%B0%84%E5%8F%98%E6%8D%A2%E4%B8%8E%E9%80%8F%E8%A7%86%E5%8F%98%E6%8D%A2/v2-362633287ba80cd94a9f4efaf1ab31d8_b.png)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E4%BB%BF%E5%B0%84%E5%8F%98%E6%8D%A2%E4%B8%8E%E9%80%8F%E8%A7%86%E5%8F%98%E6%8D%A2/v2-362633287ba80cd94a9f4efaf1ab31d8_hd.png)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E4%BB%BF%E5%B0%84%E5%8F%98%E6%8D%A2%E4%B8%8E%E9%80%8F%E8%A7%86%E5%8F%98%E6%8D%A2/v2-1cb9c5539fa00b0a06aa0a2a367f4d42_b.png)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E4%BB%BF%E5%B0%84%E5%8F%98%E6%8D%A2%E4%B8%8E%E9%80%8F%E8%A7%86%E5%8F%98%E6%8D%A2/v2-1cb9c5539fa00b0a06aa0a2a367f4d42_hd.png)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E4%BB%BF%E5%B0%84%E5%8F%98%E6%8D%A2%E4%B8%8E%E9%80%8F%E8%A7%86%E5%8F%98%E6%8D%A2/20161203145641516.jpeg)
/%E7%9F%A5%E8%AF%86%E7%82%B9/%E4%BB%BF%E5%B0%84%E5%8F%98%E6%8D%A2%E4%B8%8E%E9%80%8F%E8%A7%86%E5%8F%98%E6%8D%A2/20161203151159019.jpeg)