2018年11月15日 下午1:40
核心知识点:
- TCP连接释放
- TCP拥塞控制算法(纸质笔记里有)
《TCP/IP详解》读书笔记 - 淘帖 - 即时通讯开发者社区!
- 强化了认识:每一个数据包都带有下一个数据包的编号
- 这个编号在tcp中起到了很关键的作用
- 比如说:tcp是按字节进行传输的

- 比如说:tcp是按字节进行传输的
TCP-IP详解:滑动窗口(Sliding Window) - 深邃 精致 内涵 坚持 - CSDN博客
- TCP的滑动窗口和AQR的滑动窗口原理不同

- 规定好的协议总要操作系统实现了才能使用,而socket就是操作系统实现的
- socket、bind、listen、accept、connect一系列都是操作系统提供的接口用于实现tcp协议相关的功能
通俗大白话来理解TCP协议的三次握手和四次分手 · Issue #14 · jawil/blog · GitHub
- HTTP连接
- 由于HTTP在每次请求结束后都会主动释放连接,因此HTTP连接是一种“短连接”
- 套接字(socket)概念
- 为了区别不同的应用程序在同一个端口的进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(Socket)接口。
- 应用层可以和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
- 创建Socket连接时,可以指定使用的传输层协议,Socket可以支持不同的传输层协议(TCP或UDP)
- 为什么要三次握手?
- 防止了服务器端的一直等待而浪费资源。
- 为什么要四次分手?:
- 其实就是说的就是四次分手的过程,双方都是各自发送和接受,2*2=4
- 如果服务端没有发送完成Fin并接受client的ack之前,服务端都是可以接受client的数据的。
- 关键字:
- Sequence Number:用来标识从TCP发端向TCP收端发送的数据字节流,它表示在这个报文段中的的第一个数据字节在数据流中的序号;主要用来解决网络报乱序的问题;
- Acknowledgment Number:32位确认序列号包含发送确认的一端所期望收到的下一个序号,因此,确认序号应当是上次已成功收到数据字节序号加1。不过,只有当标志位中的ACK标志(下面介绍)为1时该确认序列号的字段才有效。主要用来解决不丢包的问题;
- ACK : TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1
- SYN(SYNchronization) : 在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1. 因此, SYN置1就表示这是一个连接请求或连接接受报文。
- FIN (finis)即完,终结的意思, 用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
【Unix 网络编程】TCP状态转换图详解_TCP_wenqian ‘blog-CSDN博客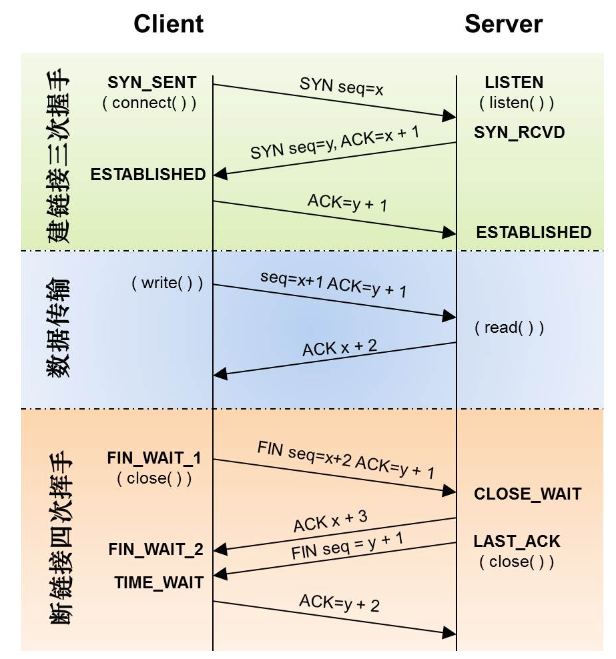
- 面向报文
- 发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付给IP层。既不拆分,也不合并,而是保留这些报文的边界,因此,应用程序需要选择合适的报文大小。


/%E5%B7%A5%E7%A8%8B/win%E7%8E%AF%E5%A2%83/%E7%8E%AF%E5%A2%83%E5%8F%98%E9%87%8F.PNG)