2018年10月11日 上午10:48
- 二维情况下:
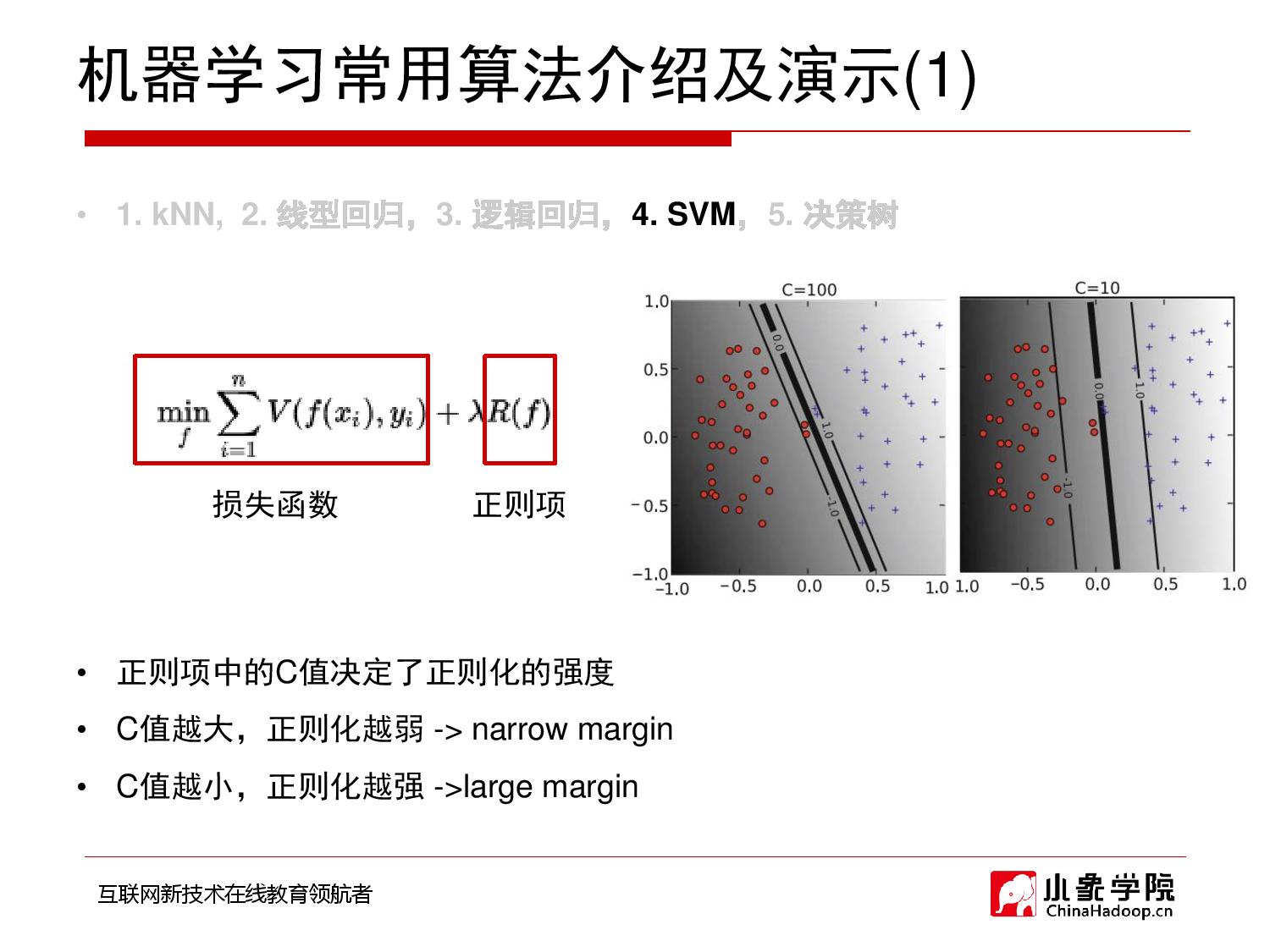
- 逻辑回归优化的目标是:min:loss
- SVM优化的目标是:max:分类器间隔
- 也可以理解为:max:分类器间隔 是 逻辑回归中loss的其中一种。
- 多维情况下:
- SVM可以认为是逻辑回归的发展,逻辑回归函数是SVM二维上其中一种核函数
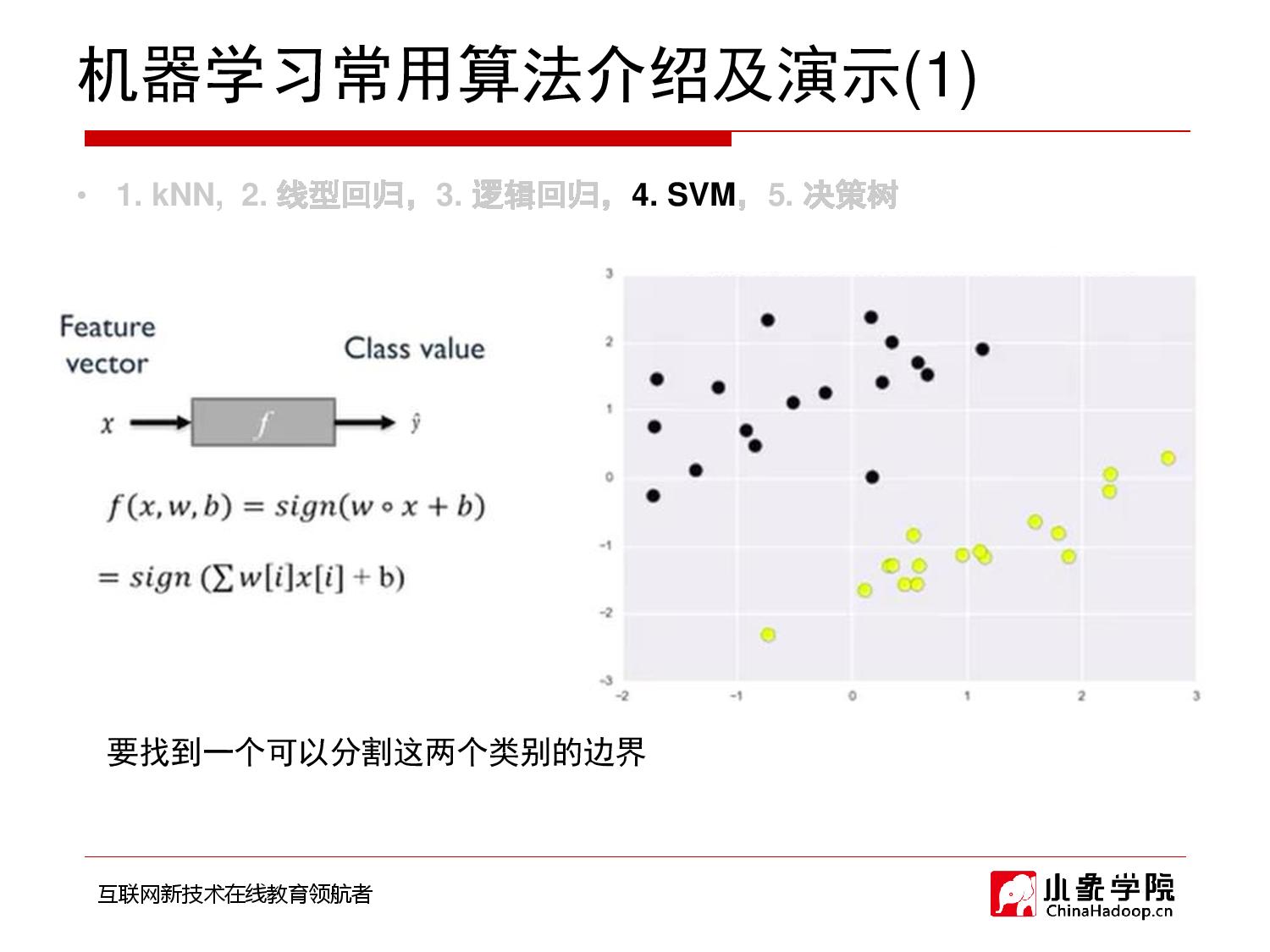
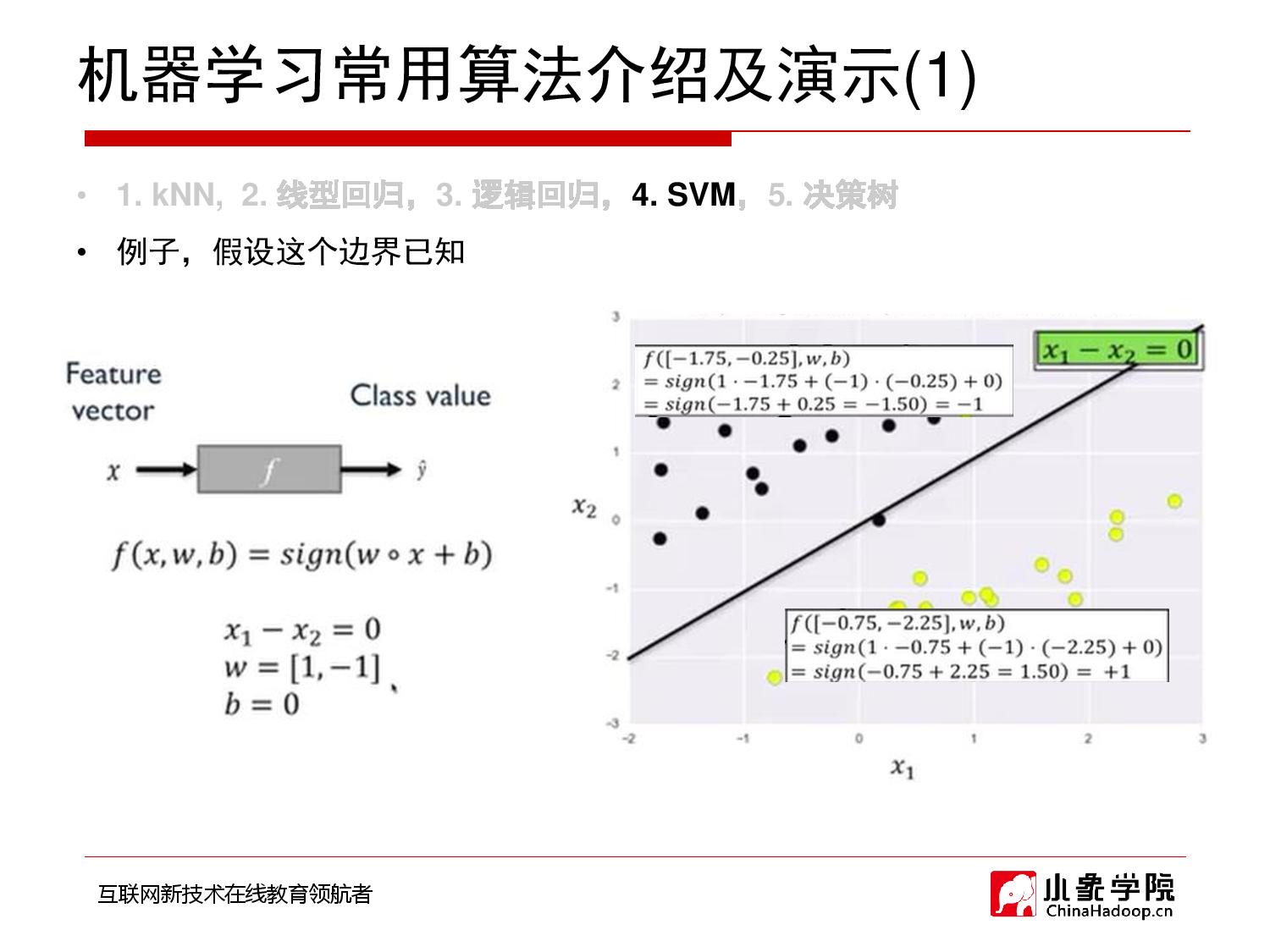
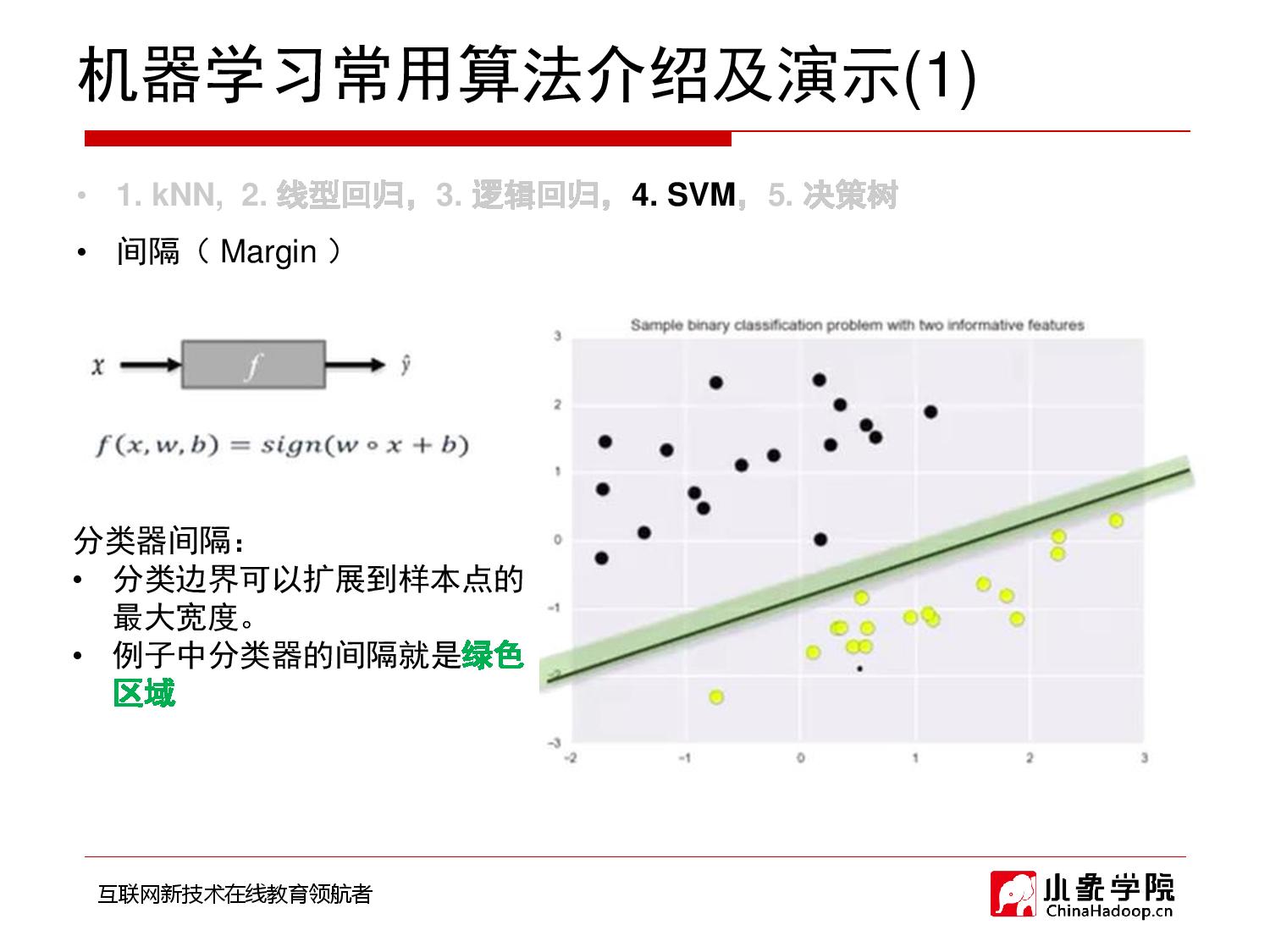
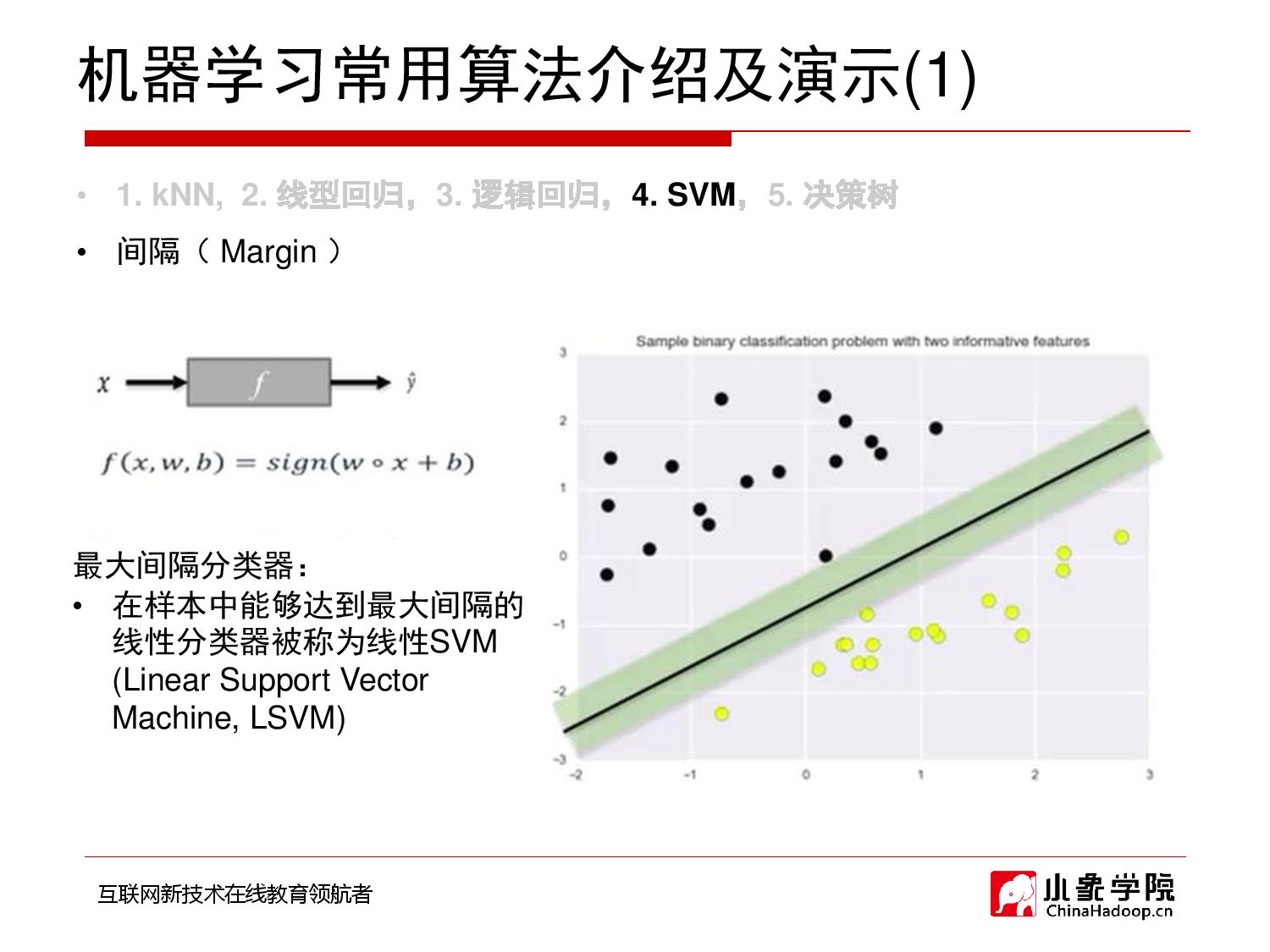

2018年10月11日 上午10:48
2018年10月11日 上午10:23




2018年10月11日 上午10:20
2018年10月9日 下午10:47
算法杂货铺——分类算法之决策树(Decision tree) - T2噬菌体 - 博客园
特征属性为连续值时,如何使用ID3算法,没看懂
有个问题是:如何证明ID3和C45是可行的?
这个问题我现在认为不是我应该思考的问题。这个问题要从数学的角度去解决。而我更应该关注的是什么问题呢?
首先决策树的一定是:判定条件是量化的
决策树中的每个“结构元素”代表着啥?
构造决策树的关键性内容:
分裂属性分为三种不同的情况:
ID3和C45的不同:
如果属性用完了怎么办?
减枝
2018年10月9日 下午9:41
朴素贝叶斯分类器的应用 - 阮一峰的网络日志
弄懂特征是离散情况的例子:
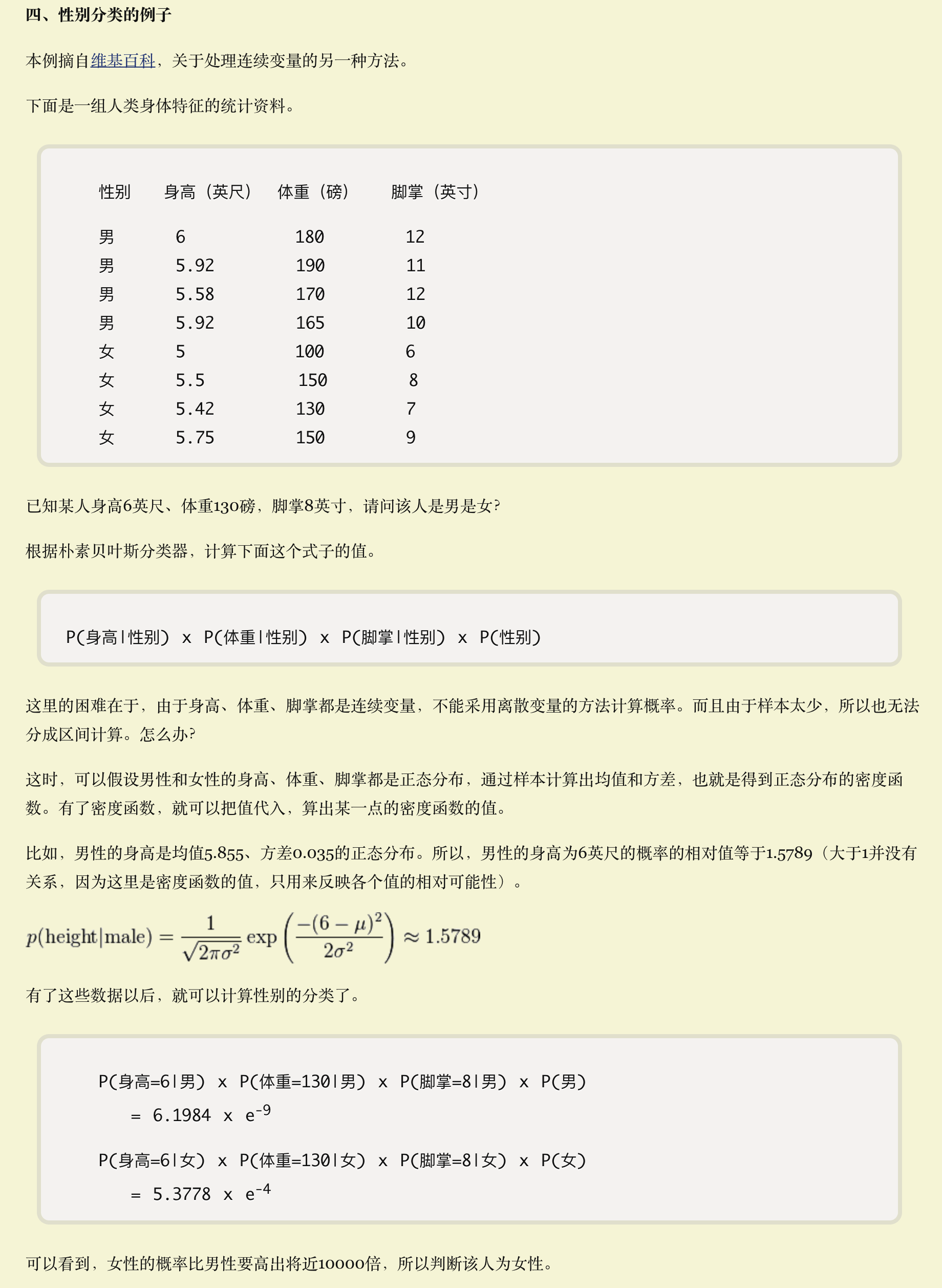




方差和均值是如何算出来的?
2018年10月8日 下午11:31
从理解的直观的角度去分析一下adaboost:
Adaboost算法原理分析和实例+代码(简明易懂) - CSDN博客
2018年10月6日 下午11:20
2018年10月4日 上午11:08
2018年10月4日 上午10:59
最简单易懂的GAN(生成对抗网络)
这篇文章中提到:机器学习和强化学习的本质区别,和认识
2018年10月4日 上午10:09
2018年10月4日 下午8:26
最简单易懂的GAN(生成对抗网络)教程:从理论到实践(附代码) | 雷锋网
2019年4月21日 下午8:55
新的理解: